📝 Paper Summary
LLM-based Recommendation
Sequential Recommendation
TransRec bridges the gap between recommendation items and language space by using multi-facet identifiers (IDs, titles, attributes) and a position-free constrained generation mechanism.
Core Problem
Existing LLM-based recommenders struggle with item indexing (IDs lack semantics, titles lack distinctiveness) and grounding (LLMs generate invalid or out-of-corpus identifiers).
Why it matters:
- Pure ID-based methods prevent LLMs from using their semantic knowledge, hurting generalization in cold-start scenarios
- Pure title-based methods confuse items with similar names, leading to poor recommendation accuracy
- Unconstrained generation requires expensive post-hoc matching steps to map generated text back to valid items
Concrete Example:
A user watches 'The Matrix'. An ID-based model sees 'ID: 15308' and misses the sci-fi context. A title-based model might suggest a documentary with 'Matrix' in the name due to semantic overlap, ignoring interaction patterns. Furthermore, the LLM might hallucinate a non-existent movie title.
Key Novelty
Transition Paradigm for Recommender (TransRec)
- Multi-facet indexing: Represents every item simultaneously as a numeric ID (for distinctiveness), a title (for semantics), and attributes (for supplementary info)
- Position-free constrained generation: Uses a specialized data structure (FM-index) to force the LLM to generate only valid substrings found in the item corpus, preventing hallucinations
Architecture
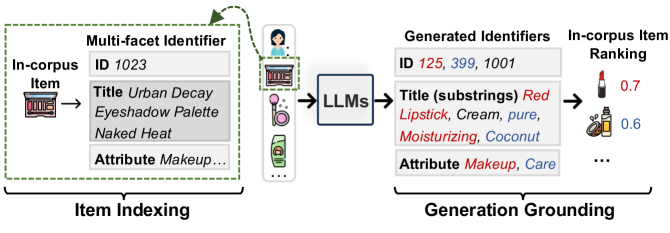
The overall framework of TransRec, illustrating the two main stages: Item Indexing (Multi-facet) and Generation Grounding.
Evaluation Highlights
- Outperforms state-of-the-art baselines on three real-world datasets (Amazon Beauty, Sports, Toys)
- Significant improvements in cold-start scenarios, demonstrating better generalization due to semantic grounding
- Eliminates the need for expensive post-generation matching (like L2 distance) by enforcing valid identifier generation during inference
Breakthrough Assessment
7/10
Solid contribution addressing the specific disconnect between continuous semantic space (LLMs) and discrete item space (RecSys). The multi-facet approach is logical and effective.