📝 Paper Summary
LLM-based Recommendation
Sequential Recommendation
BEAR aligns LLM training with inference by adding a regularization term that ensures every token of a positive item ranks high enough to survive the greedy pruning of beam search.
Core Problem
Supervised Fine-Tuning (SFT) maximizes the global probability of positive items, but inference uses Beam Search which greedily prunes sequences with low-probability prefixes.
Why it matters:
- High-probability items are frequently discarded early because their initial tokens do not rank in the top candidates (training-inference inconsistency)
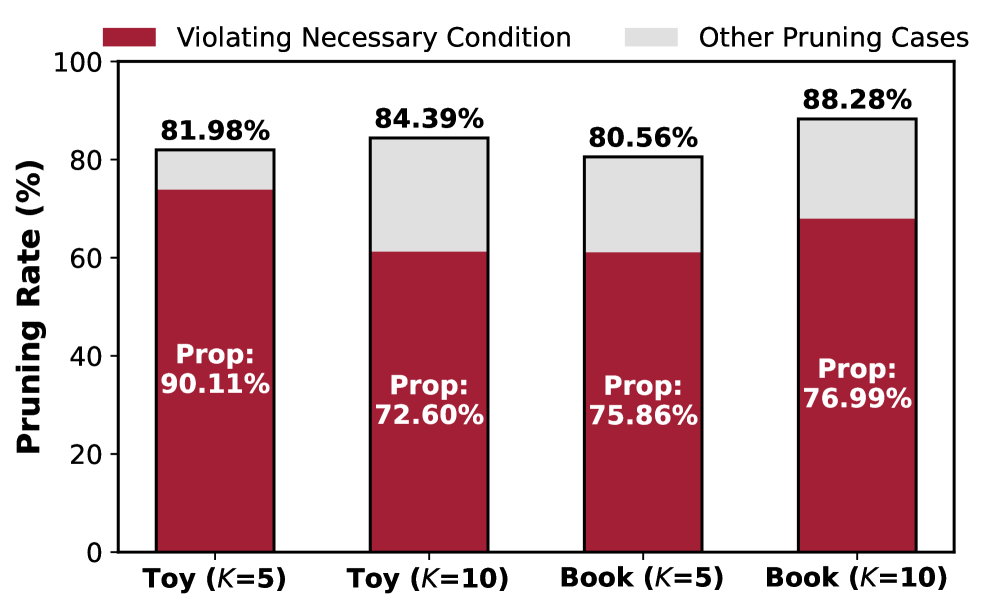
- Empirical analysis shows over 80% of positive items with top-B global probability are pruned before reaching final recommendations in standard models
Concrete Example:
Consider the item 'Bocchi the Rock!' with the highest overall probability (23%). Beam search with width 2 might prune the prefix 'Bocchi' (25%) if two other prefixes like 'The' (30%) and 'A' (45%) are higher, causing the correct item to never be retrieved.
Key Novelty
Beam-Search-Aware Regularization (BEAR)
- Instead of computationally expensive simulation of beam search during training, BEAR optimizes a 'necessary condition' for retrieval: every token must rank in the top-B candidates.
- Introduces a differentiable regularization term using a sigmoid relaxation to penalize the 'pruning margin' (gap between token probability and the B-th best candidate's probability).
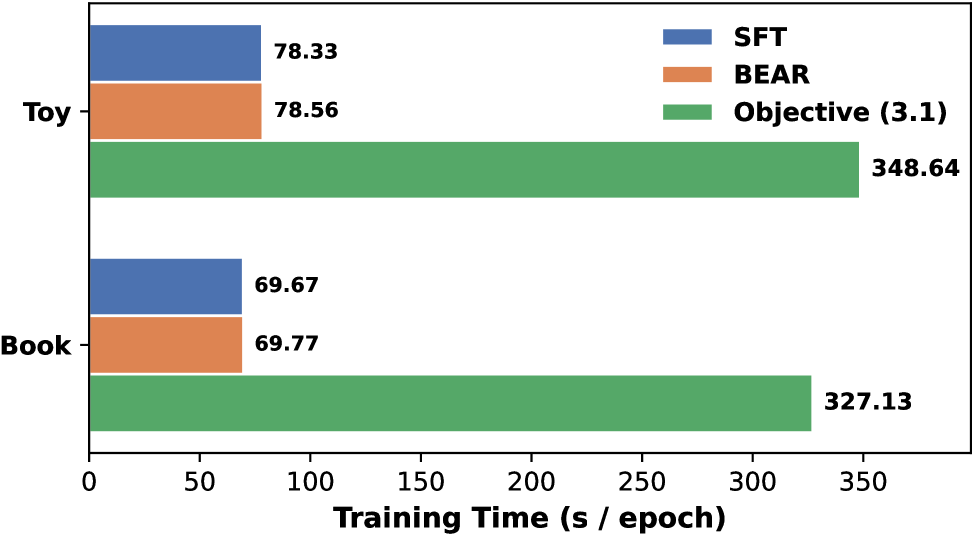
- Achieves alignment between the training objective and the greedy pruning mechanism of inference without requiring additional forward passes.
Architecture
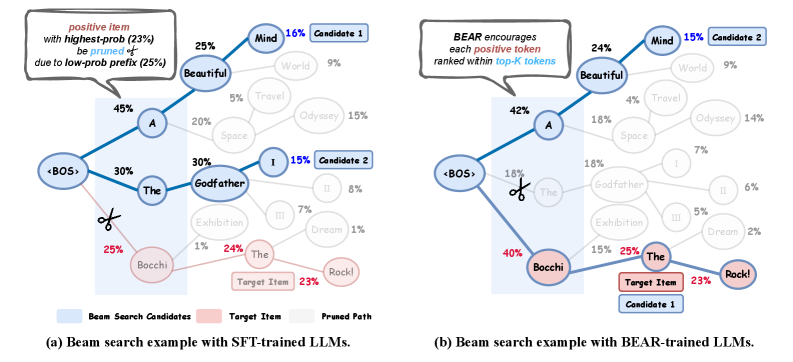
Conceptual illustration of the Training-Inference Inconsistency. Shows how an item with the highest global probability can be pruned early by beam search due to a low-probability prefix.
Evaluation Highlights
- Outperforms 9 state-of-the-art fine-tuning baselines across four real-world datasets
- Achieves an average performance improvement of 12.50% over baselines
- Incurs negligible computational overhead compared to standard SFT, unlike naive beam search simulation methods
Breakthrough Assessment
8/10
Identifies a fundamental disconnect between SFT and Beam Search in LLM recommenders. The solution is theoretically grounded (necessary condition), highly efficient (no extra forward passes), and yields significant empirical gains.