📝 Paper Summary
Membership Inference Attacks (MIA)
LLM-based Recommendation Systems
Privacy in Large Language Models
The paper proposes a membership inference attack against LLM-based recommenders that uses knowledge distillation with distinct strategies for member and non-member data to create a highly discriminative reference model.
Core Problem
Traditional shadow model-based membership inference attacks (MIAs) are ineffective against LLMs due to the massive scale of training data and the difficulty of mimicking target model behavior.
Why it matters:
- Privacy risks: Attackers can determine if specific user interaction records were used to fine-tune a recommendation model, potentially leaking sensitive user history.
- Existing shadow models fail because they cannot match the complexity or performance of large target models (LLMs).
- Reference-based attacks often require impractical access to the target model's training data distribution.
Concrete Example:
In a recommendation scenario, two data samples might differ only by one item in a user's history. Single-feature attacks (like Perplexity thresholds) fail to distinguish them because their textual similarity is high, while shadow models fail because they simply try to mimic the target without emphasizing the member/non-member boundary.
Key Novelty
Distillation-based Reference Model with Feature Fusion
- Instead of mimicking the target model (like shadow models), the reference model is distilled to maximize the behavioral difference between member and non-member data.
- Uses 'hard labels' (ground truth) to train on members (maximizing performance) and 'soft labels' (teacher logits) on non-members (mimicking teacher behavior regardless of quality), creating a divergence gap.
- Combines multiple features (confidence, entropy, loss, hidden states) via an MLP rather than relying on a single metric like perplexity.
Architecture

The two-stage pipeline of the proposed Membership Inference Attack paradigm.
Evaluation Highlights
- Outperforms shadow model baselines significantly on T5-base fine-tuned models; shadow models performed near random guessing (AUC ~0.50) while the proposed method achieved much higher AUC.
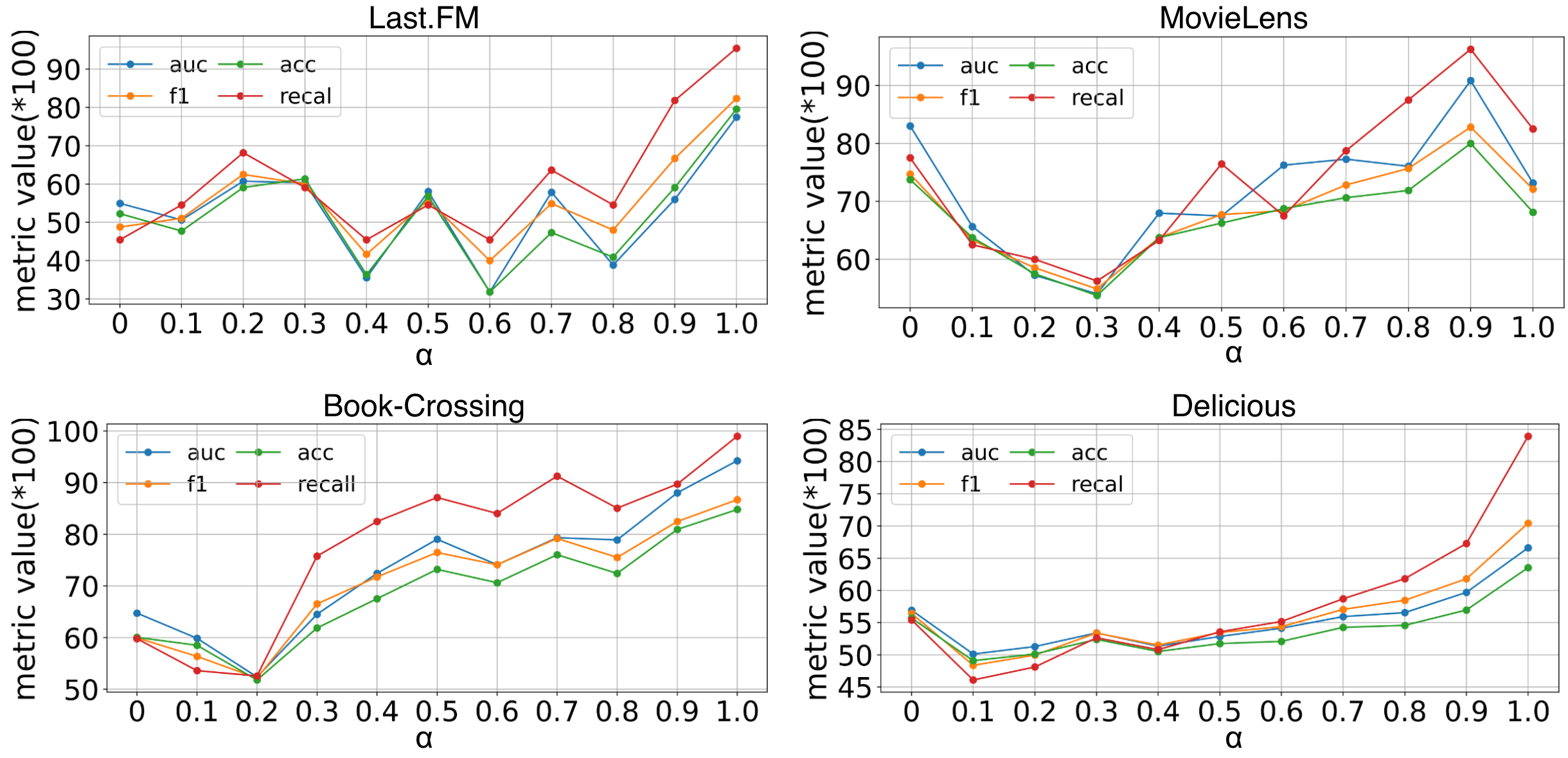
- Fused features consistently outperform individual features (like Loss or Entropy alone) across multiple datasets (Last.FM, MovieLens, Book-Crossing, Delicious).
- Demonstrates effectiveness across diverse LLM architectures (T5, GPT-2, LLaMA3) where traditional baselines often fail to beat random guessing.
Breakthrough Assessment
7/10
Offers a clever reframing of the reference model's purpose (maximizing distinction rather than imitation) which addresses a key bottleneck in LLM privacy attacks. Results are strong against baselines, though the threat model assumes specific background knowledge.