📝 Paper Summary
LLM-enhanced Recommender Systems
Representation Alignment
DaRec improves recommendation by disentangling LLM and collaborative model representations into shared and specific components, preventing the noise transfer inherent in perfect alignment strategies.
Core Problem
Directly aligning LLM and collaborative filtering representations (e.g., via contrastive learning) is sub-optimal because it forces the distinct 'specific' information of each modality to merge, introducing noise.
Why it matters:
- LLMs and collaborative models rely on fundamentally different data (natural language vs. interaction graphs), creating a natural semantic gap
- Theorem 1 proves that reducing this representation gap to zero theoretically bounds the optimal error by the 'information gap' (Delta p), meaning perfect alignment hurts performance
- Simply mapping representations into the same space introduces irrelevant noise from modality-specific features
Concrete Example:
If a collaborative model learns user preferences from clicks, and an LLM learns from review text, forcing their embeddings to be identical (zero gap) discards the unique, complementary signals each modality provides, degrading downstream accuracy.
Key Novelty
Disentangled Structure Alignment
- Separates (disentangles) the latent representations of both the LLM and the recommender into 'shared' (common semantics) and 'specific' (modality-unique) components using projection layers
- Aligns only the 'shared' components using global structure alignment (similarity matrices) and local structure alignment (adaptive preference clustering), rather than point-wise vector alignment
Architecture
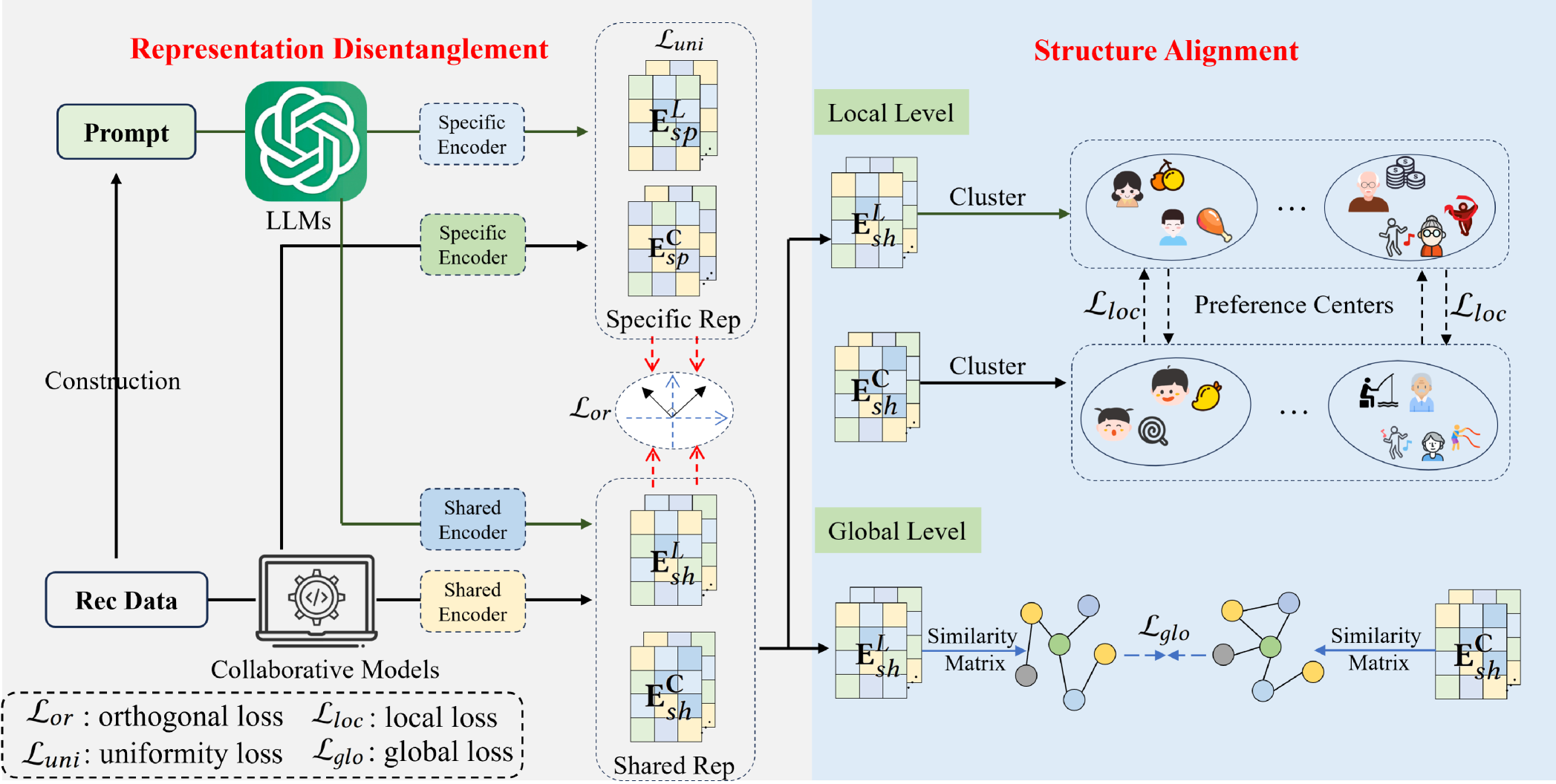
The overall DaRec framework, illustrating the disentanglement of representations and the dual-level (global and local) structure alignment.
Breakthrough Assessment
7/10
The theoretical proof that 'zero gap' alignment is sub-optimal is a strong contribution that challenges the prevailing contrastive learning paradigm in this sub-field.