📝 Paper Summary
LLM-based Recommender Systems (LRS)
Knowledge-enhanced Recommendation
CoCo improves recommendation by dynamically generating user-specific soft prompts to extract personalized knowledge from LLMs and selectively fine-tuning the LLM when its semantic outputs conflict with behavioral signals.
Core Problem
Current LLM-based recommenders use static, one-size-fits-all prompts that fail to capture diverse user interests, and they often integrate LLM knowledge superficially without resolving conflicts between semantic reasoning and behavioral history.
Why it matters:
- Static prompts cannot adapt to the multi-faceted nature of user preferences (e.g., some users prioritize price, others brand), limiting the relevance of extracted knowledge
- LLM outputs are probabilistic and can introduce noise or 'hallucinations' that degrade recommendation accuracy if blindly trusted
- Superficial fusion fails to align the semantic latent space of LLMs with the behavioral latent space of recommenders, leading to suboptimal performance
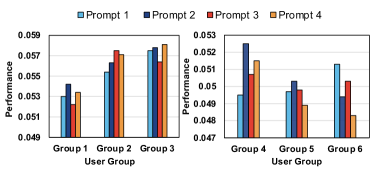
Concrete Example:
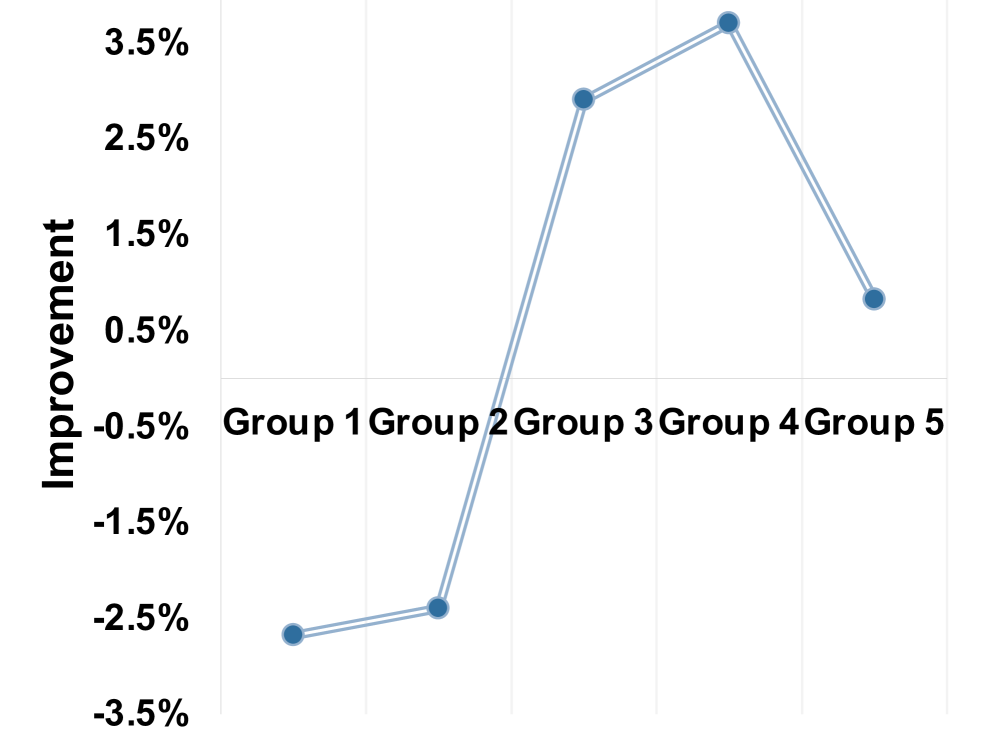
In a pilot study, a gender-guided prompt improved recommendations for one user group but hurt performance for another compared to an age-guided prompt. Furthermore, for some groups, adding LLM knowledge actually decreased accuracy due to distributional divergence between the LLM's semantic space and the recommender's behavioral space.
Key Novelty
Collaboration-Contradiction Fusion Framework (CoCo)
- Collaboration Enhancement: Uses a Vector Quantization (VQ) mechanism to dynamically select optimal 'soft prompts' from a learnable codebook for each user, replacing manual templates with adaptive continuous vectors.
- Contradiction Elimination: Implements a dynamic 'judge' that compares recommendation confidence with and without LLM knowledge; if the LLM hurts performance, it triggers targeted LoRA fine-tuning to force alignment between the LLM's semantic space and the user's behavioral patterns.
Architecture
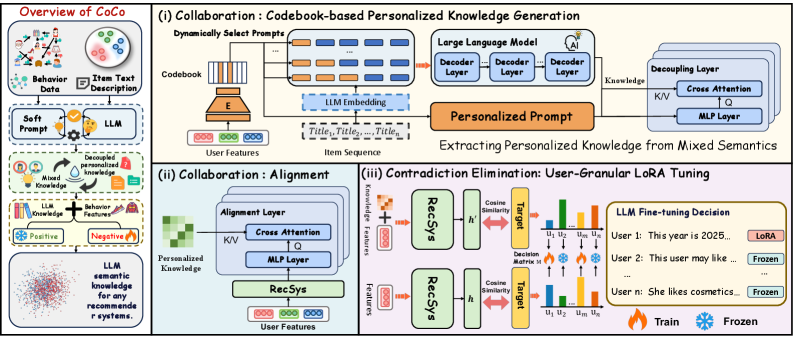
The overall CoCo framework illustrating the two main phases: Collaboration Enhancement and Contradiction Elimination.
Evaluation Highlights
- Achieves up to 8.58% improvement in recommendation accuracy over 7 state-of-the-art baselines (including KAR and R4ec) across diverse datasets.
- Online deployment on a commercial advertising platform resulted in a 1.91% increase in advertising revenue.
- Achieved 0.64% growth in Gross Merchandise Volume (GMV) in live A/B testing, validating effectiveness in high-traffic industrial scenarios.
Breakthrough Assessment
8/10
Addresses the critical 'negative transfer' problem in LLM4Rec where LLM noise hurts performance. The dynamic contradiction-based fine-tuning is a novel and practical mechanism for robustly integrating LLMs into industrial systems.