📝 Paper Summary
Conversational Recommender Systems (CRS)
LLM Agents
Tool-augmented LLMs
OMuleT is a conversational recommender system that orchestrates over 10 specific tools via a handcrafted policy to satisfy complex, real-world user requests more effectively than vanilla LLMs or code-generation policies.
Core Problem
Existing Conversational Recommender Systems (CRS) rely on synthetic queries and limited tools (1-3), failing to handle the complexity, slang, and specific constraints of real-world user requests in industrial settings.
Why it matters:
- Real user requests contain unstructured language, slang (e.g., 'ptfs'), and complex conditions (e.g., age-specific needs) that vanilla LLMs cannot process without up-to-date knowledge.
- LLMs exhibit high popularity bias and hallucination when recommending items without external grounding.
- Industrial applications require transparency and controllability, which end-to-end LLM tool generation often lacks due to 'black box' behavior.
Concrete Example:
A user asks for games for '7- and 10-year-old nephews' on tablets. A standard LLM might recommend generic popular games incompatible with tablets or inappropriate for the age, whereas OMuleT uses specific lookup tools to filter by device and age suitability.
Key Novelty
Orchestrating Multiple Tools (OMuleT)
- Decomposes the recommendation process into an intermediate 'formatted intent' stage rather than direct tool execution, ensuring transparency and easier debugging.
- Equips the LLM with a large toolbox (>10 tools) covering lookup, entity linking, retrieval, and formatting, specifically designed for the noisy nature of real user gaming requests.
- Uses a fixed, handcrafted policy to orchestrate these tools based on the extracted intent, avoiding the instability and syntax errors common in LLM-generated code policies.
Architecture
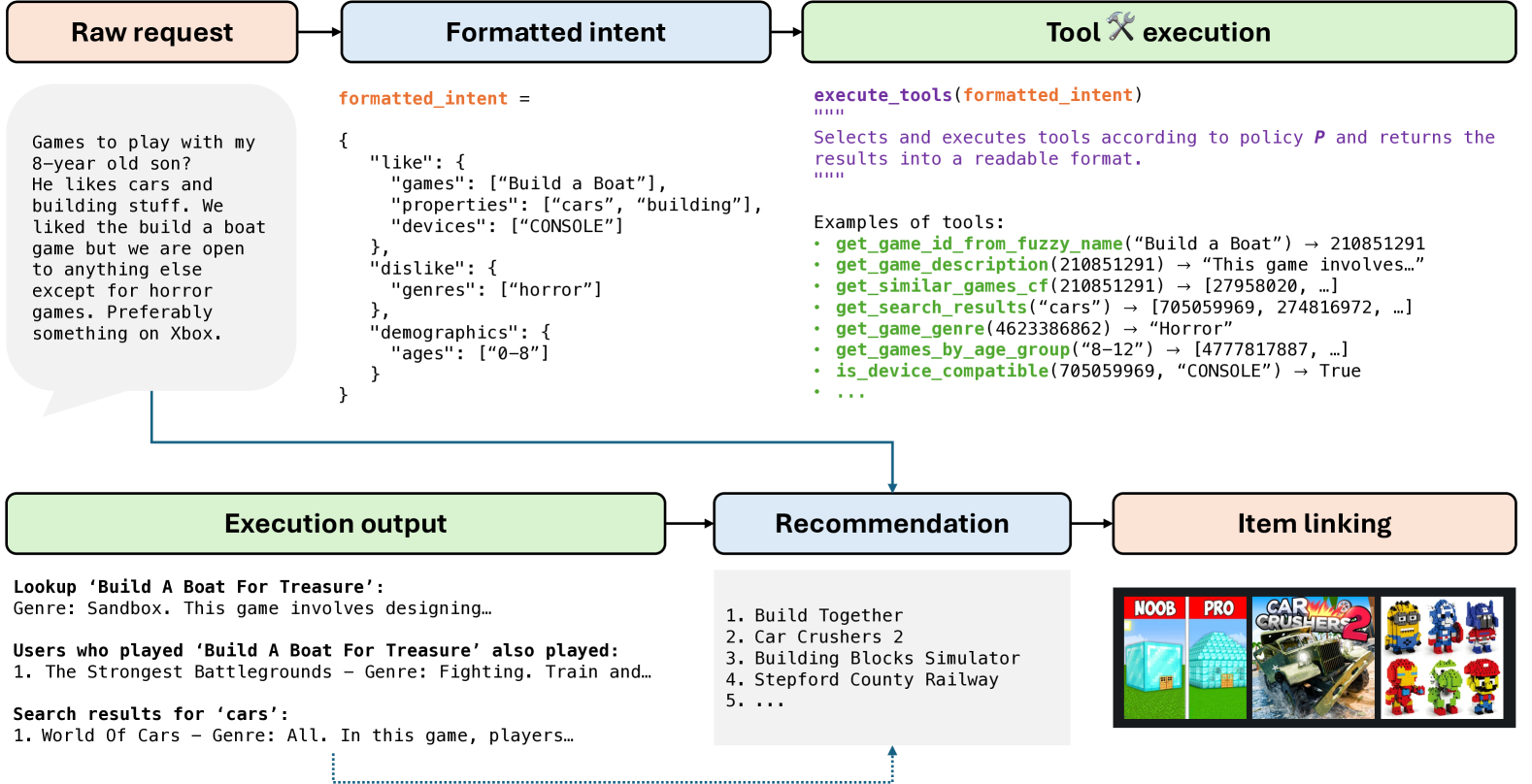
The OMuleT system pipeline processing a user request.
Evaluation Highlights
- Outperforms GPT-4o by +4.8% on Recall@5 when evaluating relevance against human-verified ground truth.
- Achieves 31.54% higher novelty (inverse popularity) compared to GPT-4o, reducing popularity bias.
- Increases item coverage (diversity) by over 4x compared to vanilla GPT-4o (12.23% vs 2.81%).
Breakthrough Assessment
7/10
Strong practical contribution addressing the gap between academic CRS and industrial reality. While the architecture (LLM + tools) is standard, the focus on >10 tools, real-world data, and a handcrafted orchestration policy offers valuable deployment insights.