📝 Paper Summary
Robust Sequential Recommendation
Defense against Poisoning Attacks
LoRec improves recommender system robustness by using Large Language Models to identify and down-weight potential fraudsters based on natural language profiles and interaction patterns.
Core Problem
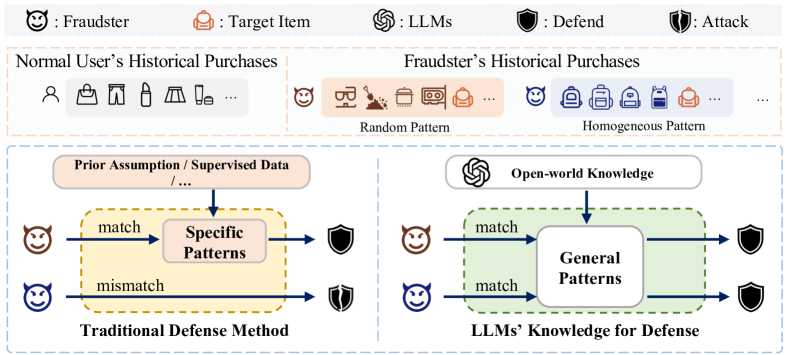
Sequential recommender systems are vulnerable to poisoning attacks where injected fraudsters manipulate item transition patterns, and existing defenses (adversarial training or rule-based detection) fail against unknown or optimization-based attacks.
Why it matters:
- Attacks can drastically skew item exposure, damaging user experience and hindering long-term system development
- Existing defenses rely on specific priors (hard-coded rules) or supervised data from known attacks, lacking generalization to new attack types like Deep Poisoning (DP)
- Adversarial training's 'min-max' paradigm often assumes attackers want to degrade overall performance, failing against attackers who aim to *promote* specific items
Concrete Example:
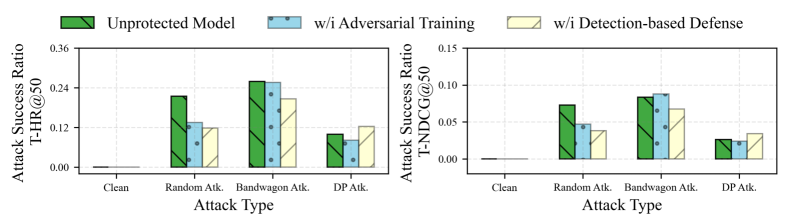
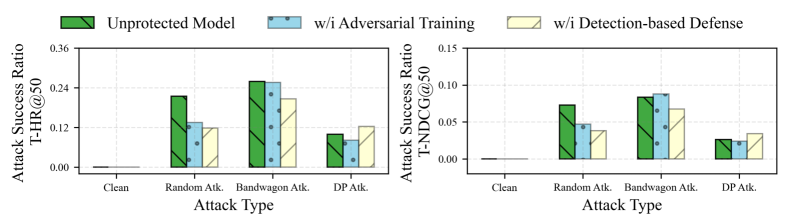
Adversarial training methods effectively defend against simple 'Bandwagon' attacks but fail against 'DP' (Deep Poisoning) attacks because DP attacks rely on optimization-based fraudster injection that deviates from the heuristic patterns adversarial training expects.
Key Novelty
LLM-Enhanced Calibration (LoRec)
- Integrates a frozen LLM to assess the 'fraudulent potential' of a user's textual profile (open-world knowledge) combined with the recommender's internal embeddings (specific knowledge)
- Uses a specialized CalibraTor (LCT) module to dynamically re-weight users during training, down-weighting probable fraudsters without requiring ground-truth fraudster labels for the entire dataset
Architecture
The LoRec framework structure, showing how the Sequential Recommender and the LLM-enhanced CalibraTor (LCT) interact.
Evaluation Highlights
- Demonstrates qualitative superiority over adversarial training against optimization-based attacks (DP) where traditional methods fail (based on Introduction claims; specific numbers not in provided text)
- Generalizes to unknown attacks by leveraging LLM open-world knowledge rather than relying solely on pre-defined heuristic rules
Breakthrough Assessment
7/10
Novel application of LLMs for *defense/calibration* in RecSys rather than recommendation itself. Addresses a critical gap (unknown attacks), though the provided text lacks the quantitative evidence to confirm the magnitude of improvement.