📝 Paper Summary
Modularized RAG pipeline
Personalized Recommendation
ChefMind is a hybrid recipe recommendation system that uses a Chain of Exploration to refine ambiguous queries into structured conditions, combining Knowledge Graphs for semantic accuracy and RAG for contextual details.
Core Problem
Personalized recipe recommendation struggles with fuzzy user intent (e.g., 'healthy comfort food'), lack of semantic accuracy, and insufficient detail coverage when using isolated technologies.
Why it matters:
- LLMs alone suffer from hallucinations, inventing non-existent recipes or unsafe cooking instructions
- Knowledge Graphs lack adaptability to dynamic, unstructured user queries despite their semantic precision
- RAG relies heavily on retrieval quality and often fails to capture structured constraints like dietary restrictions
Concrete Example:
A user asks for 'something healthy and home-style'. A keyword search might fail to find matches. An LLM might hallucinate a dish. ChefMind's CoE module refines this into structured conditions (Health=True, Tag=Home-style) for the KG, while RAG fetches specific cooking tips.
Key Novelty
Chain of Exploration (CoE) + Hybrid Retrieval (KG + RAG)
- Introduces a 'Chain of Exploration' (CoE) module acting as an intelligent frontend that progressively refines ambiguous queries into structured database constraints
- Integrates structured semantic reasoning (Knowledge Graph) with unstructured context retrieval (RAG) in a unified loop, where the KG handles hard constraints and RAG provides rich details
Architecture
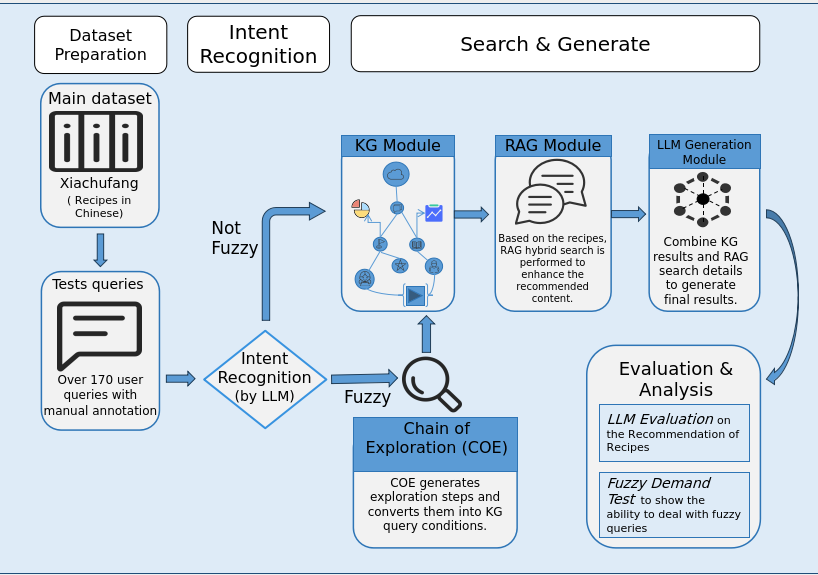
The overall framework of ChefMind, illustrating the flow from User to CoE, then branching to KG and RAG, and converging at the LLM
Evaluation Highlights
- Achieves an average score of 8.7/10 across accuracy, relevance, completeness, and clarity, outperforming LLM+RAG (6.7) and LLM+KG (6.4)
- Reduces unprocessed queries to 1.6% (2 queries), significantly lower than LLM+KG (25.6%) and LLM+RAG (17.1%)
- Demonstrates superior robustness in handling fuzzy demands, with only 1 unprocessed query in challenging batches where baselines failed on 4-5 queries
Breakthrough Assessment
7/10
Solid engineering integration of CoE, KG, and RAG for a specific domain. While the components are known, the specific hybrid architecture effectively solves the 'fuzzy intent' problem in recommendation, showing strong empirical gains.