📊 Experiments & Results
Evaluation Setup
Sequential recommendation with fairness analysis on bias origins
Benchmarks:
- ML-1M (Movie Recommendation)
Metrics:
- Item-side Fairness (epsilon)
- Covariance (between pre-training bias and SFT shift)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| ML-1M | Covariance (Pre-training bias vs SFT shift) | 0 | 0.000773 | +0.000773 |
Experiment Figures
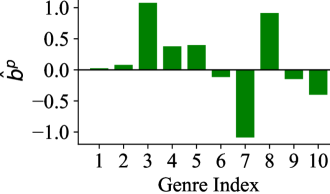
Visualization of centered biases for 10 genre groups in ML-1M, comparing Pre-training bias (Delta_p) and SFT shift (Delta_delta).
Main Takeaways
- Group-level unfairness in LRS is composite: Pre-training establishes an initial bias pattern (often due to language priors), and SFT amplifies it.
- The positive covariance between pre-training bias and SFT shift proves that standard fine-tuning reinforces existing inequities instead of aligning with the target distribution.
- Raw outputs of base LLMs (without SFT) exhibit large dispersion and irrelevant text, necessitating calibration to measure inherent bias accurately.