📝 Paper Summary
Generative Retrieval
Generative Recommendation
Purely Semantic Indexing generates unique, conflict-free document identifiers by relaxing strict nearest-centroid assignments rather than appending non-semantic tokens, preserving semantic integrity for better retrieval performance.
Core Problem
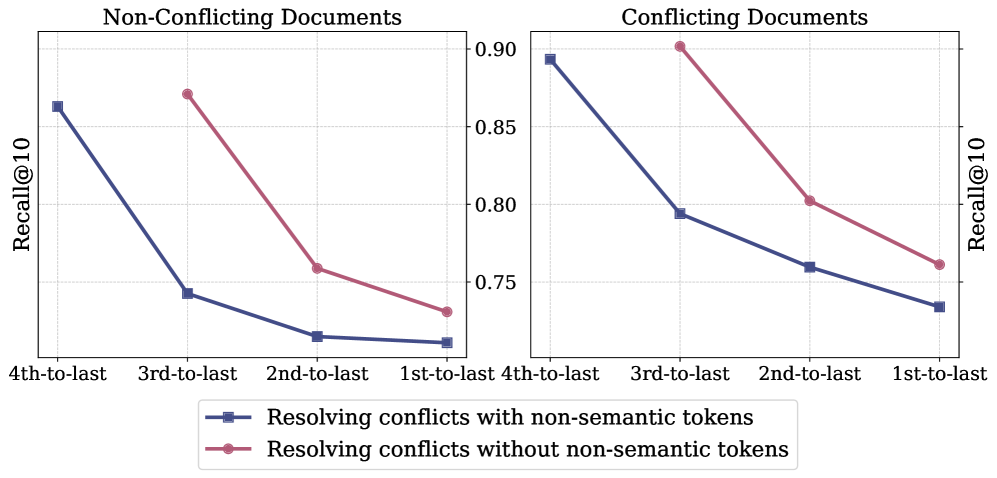
Existing semantic indexing methods assign identical IDs to similar documents, resolving conflicts by appending arbitrary non-semantic tokens (suffixes) that destroy the semantic structure and expand the search space.
Why it matters:
- Appending non-semantic tokens introduces randomness, hurting the model's ability to generalize based on semantic similarity
- The expanded token space complicates retrieval, especially in cold-start scenarios where the non-semantic suffix for unseen items is unpredictable
- Predicting the final non-semantic token causes a significant performance drop even when semantic prefixes are correct
Concrete Example:
In legacy systems, two similar movies might both map to semantic prefix '123'. To distinguish them, the system assigns '123-1' and '123-2'. The suffixes '-1' and '-2' have no meaning. A model predicting '123' has no semantic basis to choose between '1' or '2', leading to guessing and errors.
Key Novelty
Conflict-Resolution via Relaxed Quantization
- Instead of always picking the strictly nearest cluster centroid for an ID token, allow selecting the second-nearest (or k-nearest) centroid if the nearest one causes a conflict
- Prioritizes ID uniqueness over perfect reconstruction of the original embedding, ensuring every document gets a distinct ID composed entirely of meaningful semantic tokens
Architecture
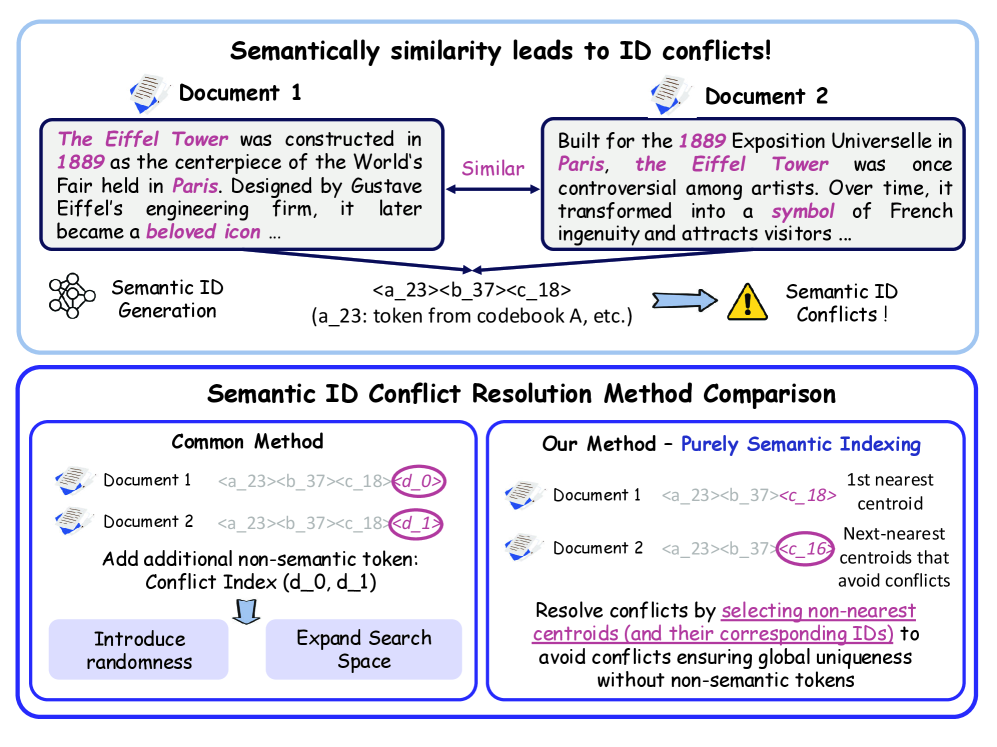
Comparison between Legacy Semantic IDs (with conflict tokens) and Purely Semantic Indexing (proposed).
Evaluation Highlights
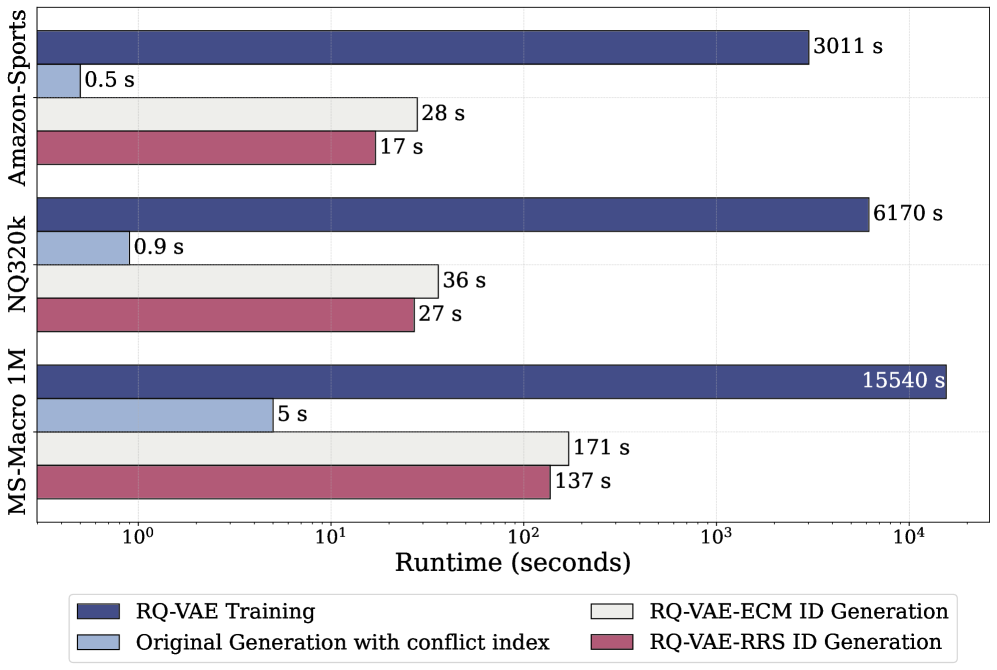
- Consistent performance gains over vanilla RQ-VAE and Hierarchical Clustering across Sequential Recommendation, Product Search, and Document Retrieval tasks
- Significantly improved cold-start performance (e.g., clear gains on items with 0 or 1 historical interaction) by eliminating unpredictable non-semantic suffixes
- Fully semantic IDs (3 levels) outperform hybrid IDs (2 levels + 1 conflict index) on Amazon Product Search, validating the benefit of semantic depth
Breakthrough Assessment
7/10
Simple yet effective fix for a pervasive problem in generative retrieval. While algorithmic innovation is moderate (search algorithms), the insight about trading reconstruction accuracy for uniqueness is valuable and empirically validated.