📝 Paper Summary
Synthetic Data Generation
Conversational Recommendation Systems (CRS)
ConvRecStudio generates realistic multi-turn conversational recommendation datasets by using LLM agents grounded in real historical user-item interactions and temporal aspect profiles.
Core Problem
Combining collaborative filtering (history-based) and conversational recommendation (dialog-based) is hindered by the lack of datasets containing both long-term interaction logs and corresponding natural language dialogs.
Why it matters:
- Current CRS models ignore long-term user history, leading to generic suggestions
- Traditional recommenders cannot interactively elicit immediate needs
- Manual collection of grounded conversational data is prohibitively expensive and requires domain expertise
Concrete Example:
A user typically buys tech gadgets (long-term preference) but explicitly asks for a 'budget-friendly speaker for a party' (immediate need). Existing datasets have either the purchase log OR the chat, but not both linked together, preventing models from learning to fuse these signals.
Key Novelty
ConvRecStudio Framework
- Constructs temporal user/item profiles from reviews to capture evolving preferences over fine-grained aspects (e.g., battery life) without manual annotation
- Uses a Semantic Dialog Plan (a DAG of dialog acts) to structure the conversation flow while allowing LLMs flexibility in phrasing
- Simulates dialogs using two role-playing LLM agents (User and System) constrained by the plan and grounded in real timestamped interactions
Architecture
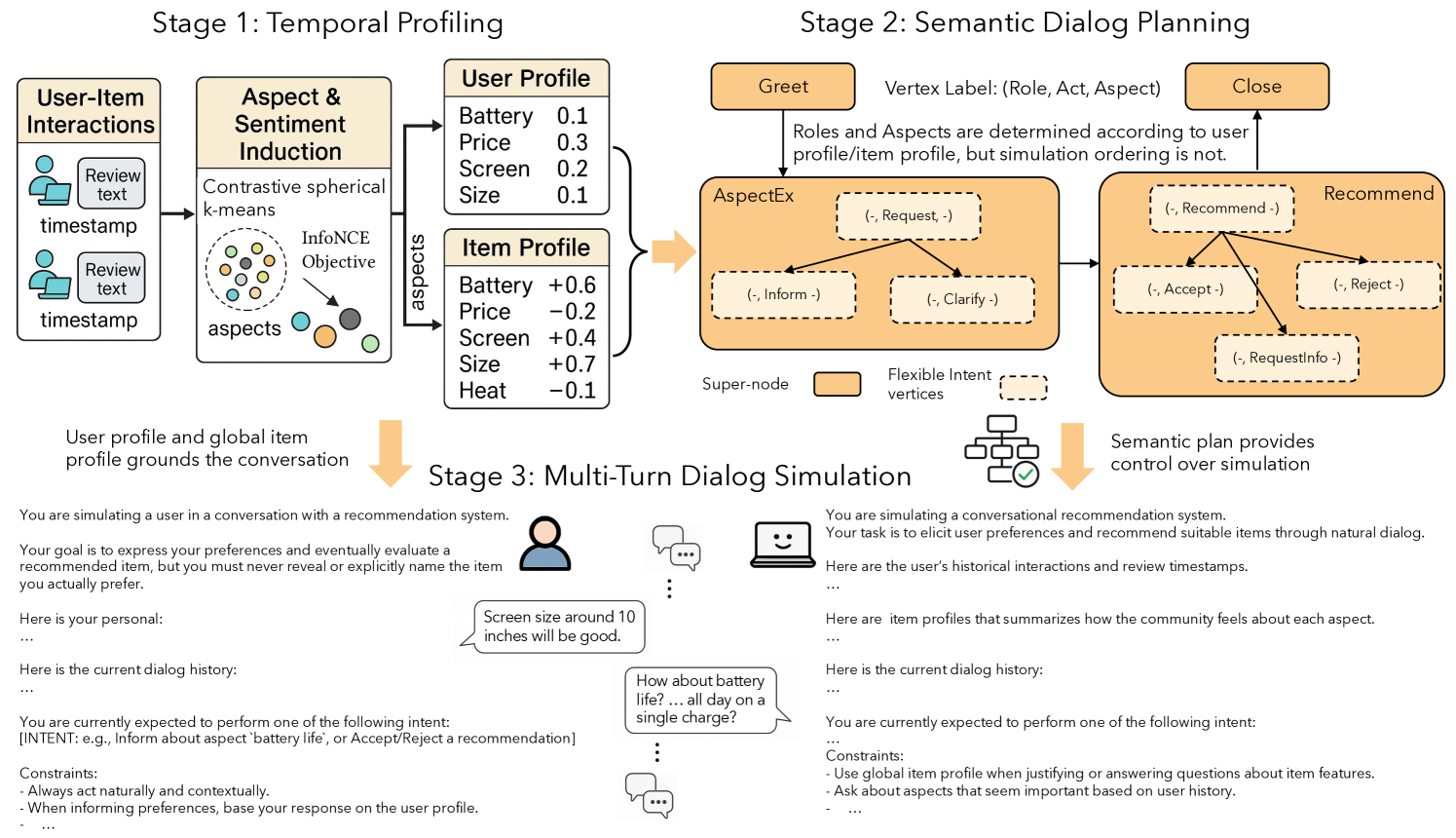
Overview of the ConvRecStudio framework pipeline.
Evaluation Highlights
- Generated over 38,000 multi-turn dialogs across three domains (MobileRec, Yelp, Amazon Electronics) grounded in real user behavior
- A proposed cross-attention model trained on this data achieves a 10.9% improvement in Hit@1 on the Yelp dataset compared to the strongest baseline
- Human evaluation confirms generated dialogs are fluent, coherent, and faithfully reflect the underlying user-item interactions
Breakthrough Assessment
8/10
Addresses a critical data scarcity bottleneck in conversational recommendation. The generated datasets enable a new class of models that fuse collaborative and conversational signals.