📝 Paper Summary
Conversational Recommender Systems (CRS)
LLM Evaluation
The paper introduces iEvaLM, an interactive evaluation framework using LLM-based user simulators, which reveals that traditional static evaluation protocols significantly underestimate ChatGPT's conversational recommendation capabilities.
Core Problem
Standard CRS evaluation relies on static, exact matching against ground-truth items in human-annotated logs, which fails to account for the interactive nature of recommendation and the ambiguity of user intent in short text segments.
Why it matters:
- Current protocols penalize powerful models like ChatGPT for asking clarification questions or suggesting valid alternatives that differ from the single ground-truth label in the dataset
- Static evaluation ignores the multi-turn interactive process, which is the core value proposition of conversational systems
- Underestimating LLMs hinders the development of more capable, general-purpose conversational agents
Concrete Example:
In a ReDial dataset example, a user vaguely asks for 'movies for a night with friends'. The static label is 'Black Panther'. ChatGPT suggests 'The Hangover' and 'Bridesmaids'. Traditional evaluation scores this as 0 accuracy, failing to recognize the validity of the suggestions or the need for clarification.
Key Novelty
iEvaLM (interactive Evaluation approach based on LLMs)
- Employs an LLM-based user simulator (powered by text-davinci-003) initialized with personas derived from ground-truth items to interact dynamically with the recommender system
- Simulates realistic user behaviors including answering clarification questions, providing feedback on recommendations, and terminating conversations upon success
- Evaluates both accuracy (Recall) and explainability (Persuasiveness) in a closed-loop interactive setting rather than static text matching
Architecture
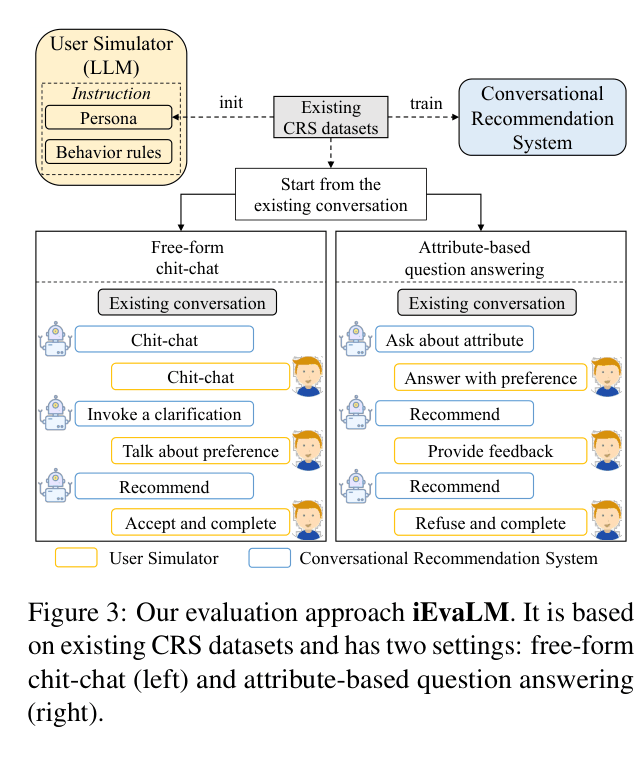
The iEvaLM evaluation framework where an LLM-based User Simulator interacts with the CRS.
Evaluation Highlights
- ChatGPT's Recall@10 on the ReDial dataset jumps from 0.174 (static evaluation) to 0.536 (interactive evaluation), surpassing state-of-the-art baselines
- The proposed LLM-based user simulator is rated significantly more natural (55% vs 11%) and useful (38% vs 31%) than a DialoGPT-based simulator in multi-turn settings
- ChatGPT achieves a Persuasiveness score of 1.331 on ReDial, significantly outperforming the best baseline UniCRS (1.015)
Breakthrough Assessment
8/10
Identifies a critical flaw in CRS evaluation that misrepresents LLM capabilities. The proposed interactive solution is practical and demonstrates a massive, previously hidden performance gap.