📝 Paper Summary
Sequential Recommendation
LLM for Recommendation
Multi-modal alignment
PAD enhances sequential recommendation by aligning LLM semantic embeddings with ID-based collaborative embeddings using characteristic kernels, then disentangling them via a frequency-aware triple-expert architecture.
Core Problem
Existing LLM-enhanced recommenders suffer from high inference latency, fail to capture full data distribution statistics due to non-characteristic alignment kernels, and experience catastrophic forgetting where alignment degrades collaborative knowledge.
Why it matters:
- Commercial systems require low latency (hundreds of items in milliseconds), making direct LLM inference impractical
- Standard contrastive alignment (e.g., InfoNCE with cosine kernels) misses higher-order statistical dependencies between modalities
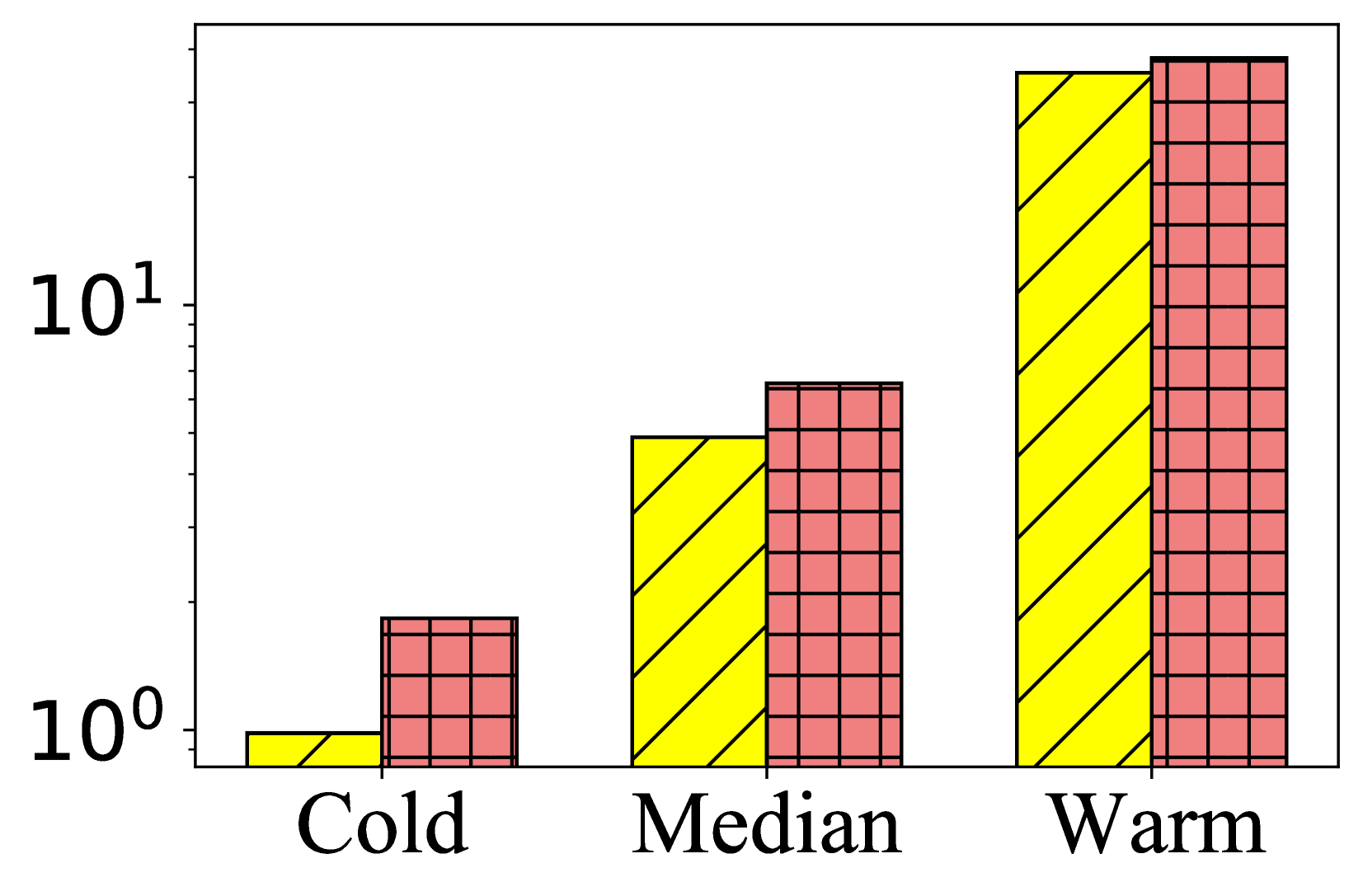
- Simply forcing text embeddings to match ID embeddings destroys the unique semantic information LLMs provide, hurting performance on cold items
Concrete Example:
When a new item appears (cold start), ID-based models have no interaction history and fail. Standard alignment methods try to map its text description to the ID space but lose the semantic nuance or overwrite the ID model's collaborative patterns, leading to suboptimal recommendations for both fresh and popular items.
Key Novelty
Pre-train, Align, and Disentangle (PAD) Framework
- Uses Multi-Kernel Maximum Mean Discrepancy (MK-MMD) with characteristic kernels (Gaussian) to align text and ID distributions, ensuring all statistical moments are matched unlike cosine-based alignment
- Introduces a 'rec-anchored' alignment loss that keeps the ID model frozen to the recommendation task during alignment, preventing the text alignment from corrupting collaborative knowledge (catastrophic forgetting)
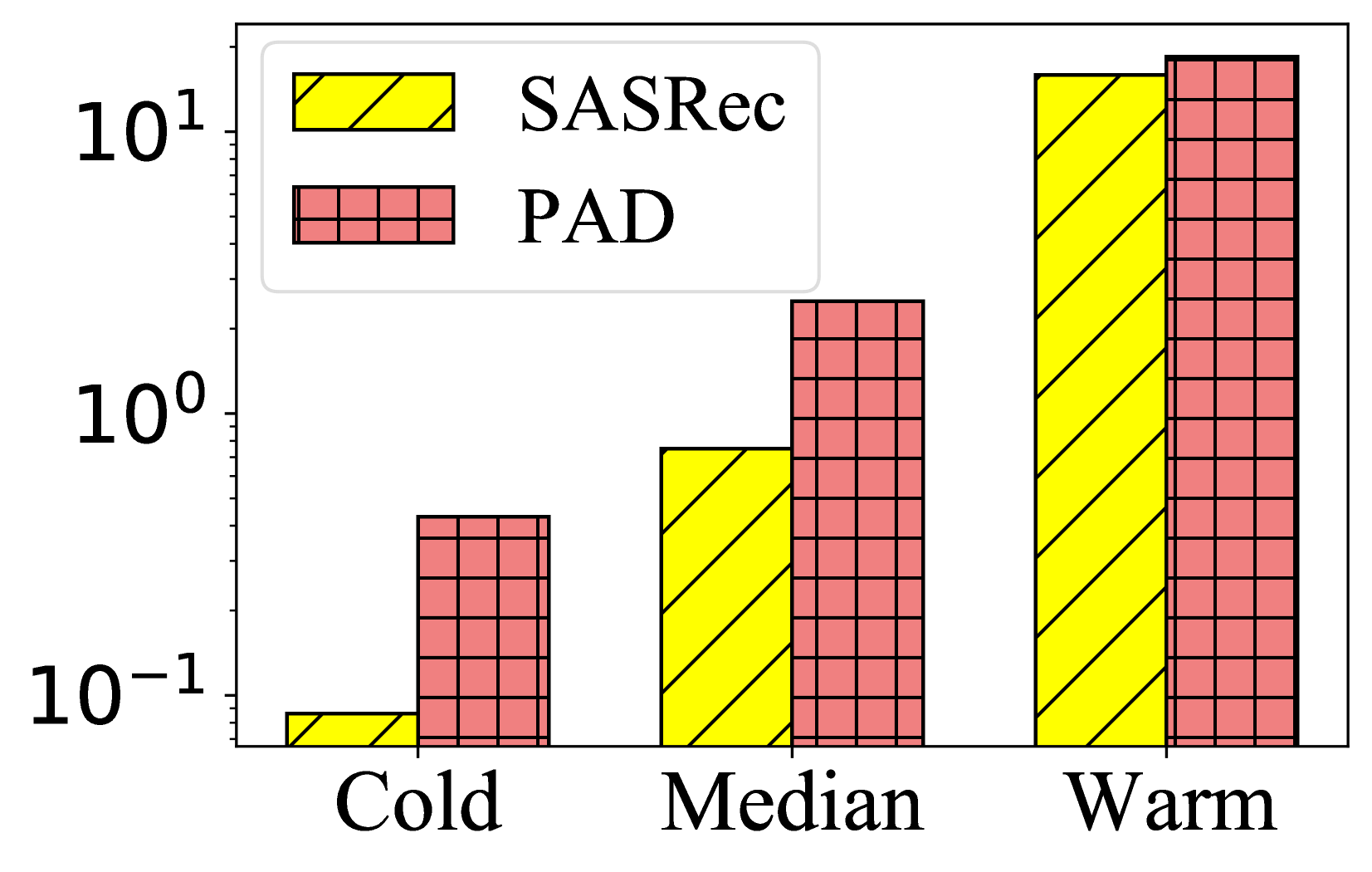
- Deploys a Triple-Expert Mixture-of-Experts (MoE) at inference: one expert for ID features, one for text features, and one for aligned features, gated by item frequency to handle cold vs. popular items dynamically
Architecture
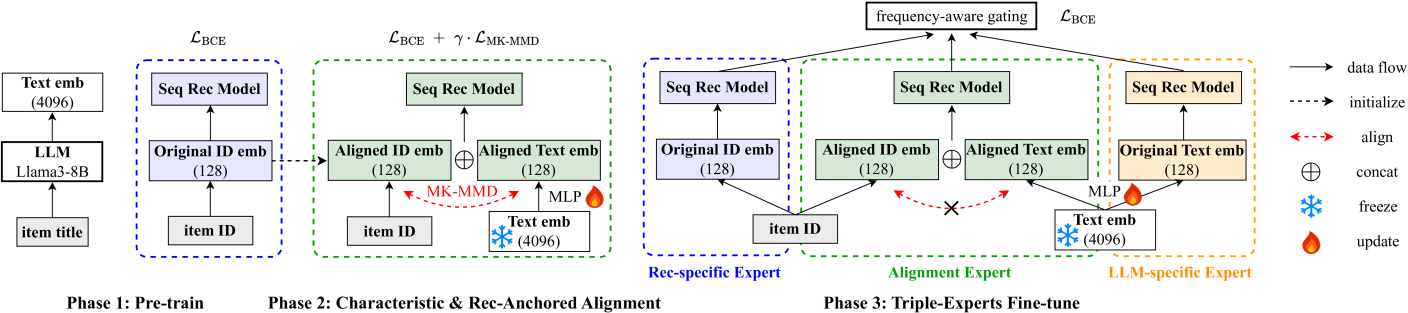
The three-phase PAD framework: (1) Pre-training SASRec and LLM, (2) Alignment via MK-MMD and Rec Loss, (3) Disentangled Triple-Expert Fine-tuning with Gating.
Evaluation Highlights
- Outperforms state-of-the-art baselines (e.g., CTRL, RLMRec) by up to 8.54% on HR@10 across three datasets (Sports, Beauty, Toys)
- Significantly improves cold-start performance, boosting NDCG@10 by ~6-13% on the Beauty dataset compared to the strongest baseline
- Eliminates catastrophic forgetting: ID-only performance drops by only ~1% after alignment compared to ~35% drops in contrastive approaches like CLIP
Breakthrough Assessment
7/10
Solid methodological improvement addressing specific weaknesses in LLM-Rec alignment (forgetting, distribution matching). The triple-expert design is a practical solution for the cold-start/warm-start trade-off.