📝 Paper Summary
Sequential Recommendation
Scaling Laws
Click-Through Rate (CTR) Prediction
LLaTTE establishes that ads recommendation follows LLM-like scaling laws when semantic features are used, enabling a two-stage architecture that offloads heavy sequence processing to an asynchronous upstream model.
Core Problem
Production recommendation systems are constrained to shallow models by strict latency budgets and rely on sparse ID features that plateau quickly, preventing them from exploiting the power-law scaling seen in LLMs.
Why it matters:
- Current industrial systems fail to capture long-term user intent because they cannot process long sequence histories (thousands of actions) in real-time
- There is a gap between research (deep transformers) and production (shallow FM-based models), limiting the adoption of scaling laws in revenue-critical systems
Concrete Example:
A standard ID-based model might learn that a user clicked 'shoes', but fails to scale performance with added depth. LLaTTE uses semantic features (content embeddings) so that adding layers continuously improves predictions about the user's intent to buy 'running gear' based on a 5000-action history.
Key Novelty
Two-Stage Semantic Scaling Paradigm
- Demonstrates that semantic features (content embeddings) are a prerequisite for scaling, effectively 'bending the curve' to allow deeper models to continue improving where ID-only models plateau
- Splits inference into an asynchronous 'Upstream' stage (massive, processes long history) and a synchronous 'Online' stage (lightweight, fuses upstream signal), preserving scaling gains under latency constraints
Architecture
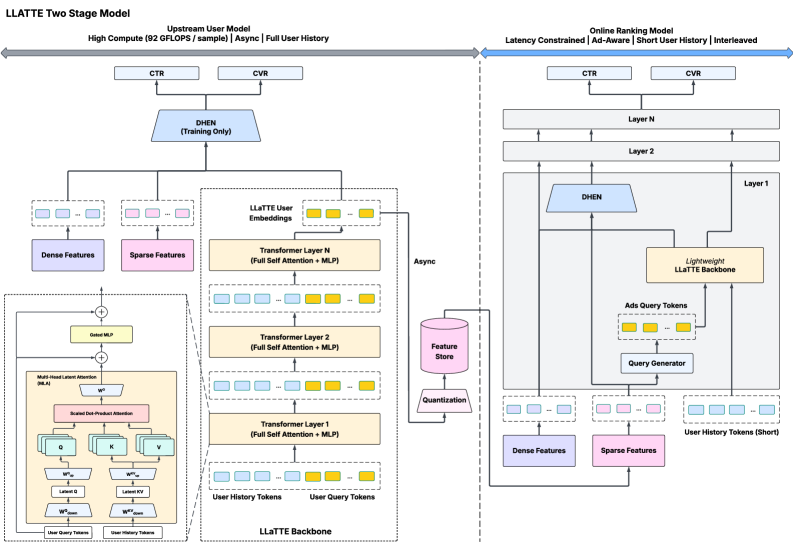
The LLaTTE architecture diagram showing the interaction between the Sequence Module (Transformer) and Non-Sequence Module (DHEN), and the two-stage deployment.
Evaluation Highlights
- +4.3% Conversion Rate (CVR) uplift on Facebook Feed and Reels in live production experiments
- +0.25% Normalized Entropy (NE) improvement on primary revenue-generating models (significant in mature ads systems)
- Achieves a ~50% Transfer Ratio, meaning half of the theoretical gain from the massive upstream model is successfully preserved in the constrained online environment
Breakthrough Assessment
9/10
Establishment of empirical scaling laws for industrial recommendation and the successful deployment of a massive multi-stage transformer at Meta's scale represents a significant operational and theoretical advance.