📝 Paper Summary
Collaborative Filtering
LLM for Recommendation
Embedding Initialization
LLMInit distills rich semantic knowledge from frozen Large Language Models into lightweight Collaborative Filtering models by selectively sampling and initializing user/item embeddings, bypassing the high computational cost of full LLM deployment.
Core Problem
Collaborative filtering (CF) models struggle with cold-start users due to random initialization, while direct LLM deployment for recommendation is computationally prohibitive and suffers from embedding collapse when scaling.
Why it matters:
- Industrial recommender systems face millions of users/items, making direct LLM inference (e.g., 7B params) unscalable due to latency and storage costs.
- Existing CF methods rely heavily on dense interaction data, failing significantly in real-world sparse or cold-start scenarios.
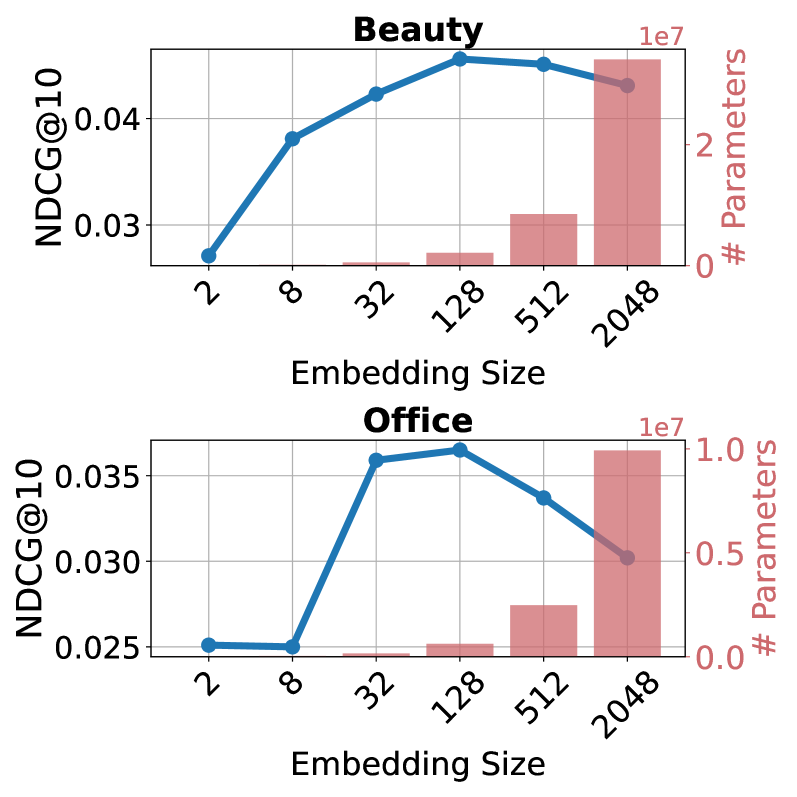
- Directly using high-dimensional LLM embeddings (e.g., 4096 dim) in CF models leads to performance degradation (embedding collapse), unlike in NLP tasks.
Concrete Example:
In the Amazon Office-Products dataset, standard LightGCN performance drops as embedding size increases beyond 128 dimensions (embedding collapse). Meanwhile, a full LLM-based recommender like LLMRec requires 7B+ parameters for inference, whereas LLMInit achieves better results with only 2M parameters by efficiently initializing a standard CF model.
Key Novelty
Selective Initialization from LLMs (LLMInit)
- Treats pre-trained LLM embeddings as a 'free lunch' source of semantic knowledge to replace random initialization in standard CF models.
- Selects specific dimensions from high-dimensional LLM vectors (via random, uniform, or variance-based sampling) to fit the smaller embedding space of CF models, avoiding embedding collapse.
- Initializes user embeddings by aggregating the selected embeddings of items they have interacted with, handling users without explicit context.
Architecture
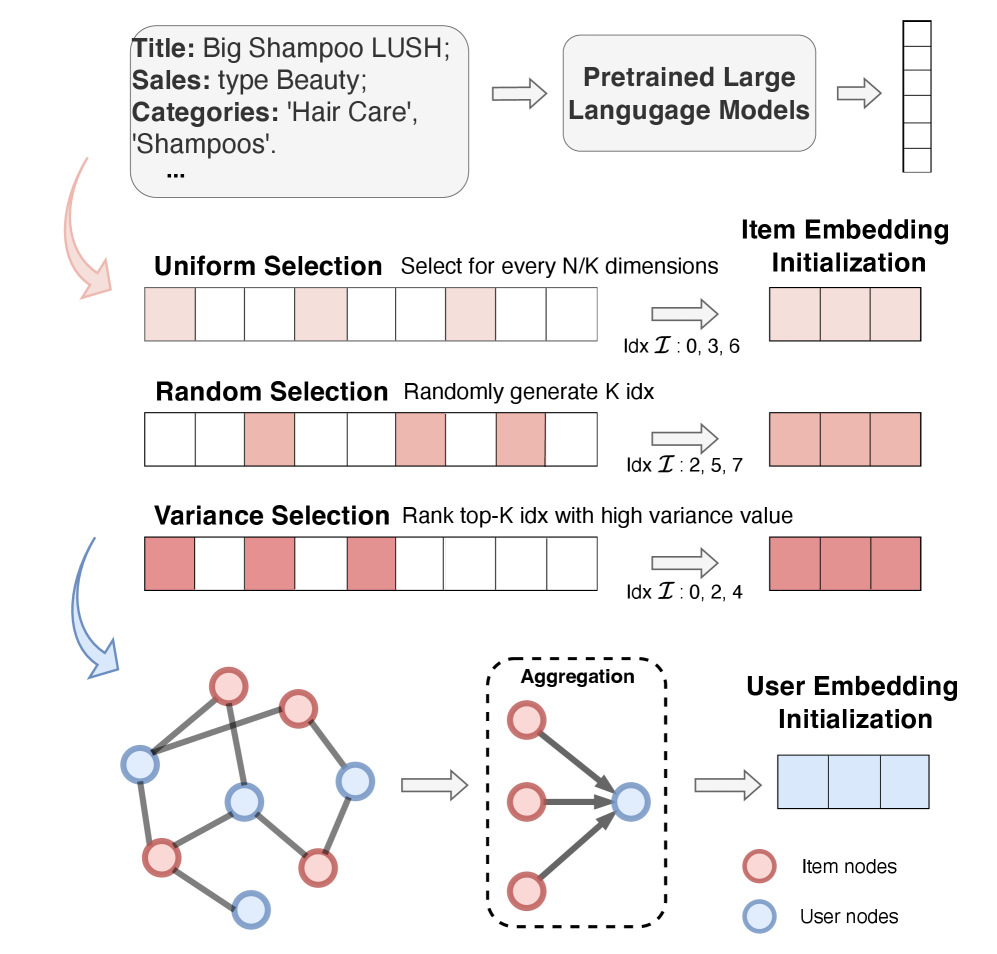
The LLMInit framework pipeline. It illustrates the flow from Raw Metadata -> LLM -> Semantic Latent Embedding -> Selective Initialization -> User Aggregation -> CF Model.
Evaluation Highlights
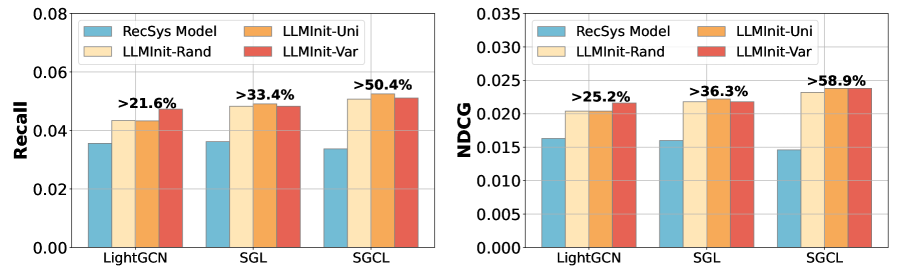
- +58.9% NDCG improvement for SGCL on cold-start users in Amazon Beauty when initialized with LLMInit-Var.
- Consistently outperforms standard initialization across 3 baselines (LightGCN, SGL, SGCL) and 4 datasets, with gains up to +22.8% Recall@10 on Office-Products.
- Achieves SOTA performance with ~2M trainable parameters, compared to 7B+ parameters for LLM-based baselines like LLMRec.
Breakthrough Assessment
7/10
A practical, efficient solution for integrating LLMs into industrial recommendation. While methodologically simple (initialization strategy), the empirical gains in cold-start scenarios and the solution to embedding collapse are significant and highly adoptable.