📝 Paper Summary
LLM-based Recommender Systems
Sequential Recommendation
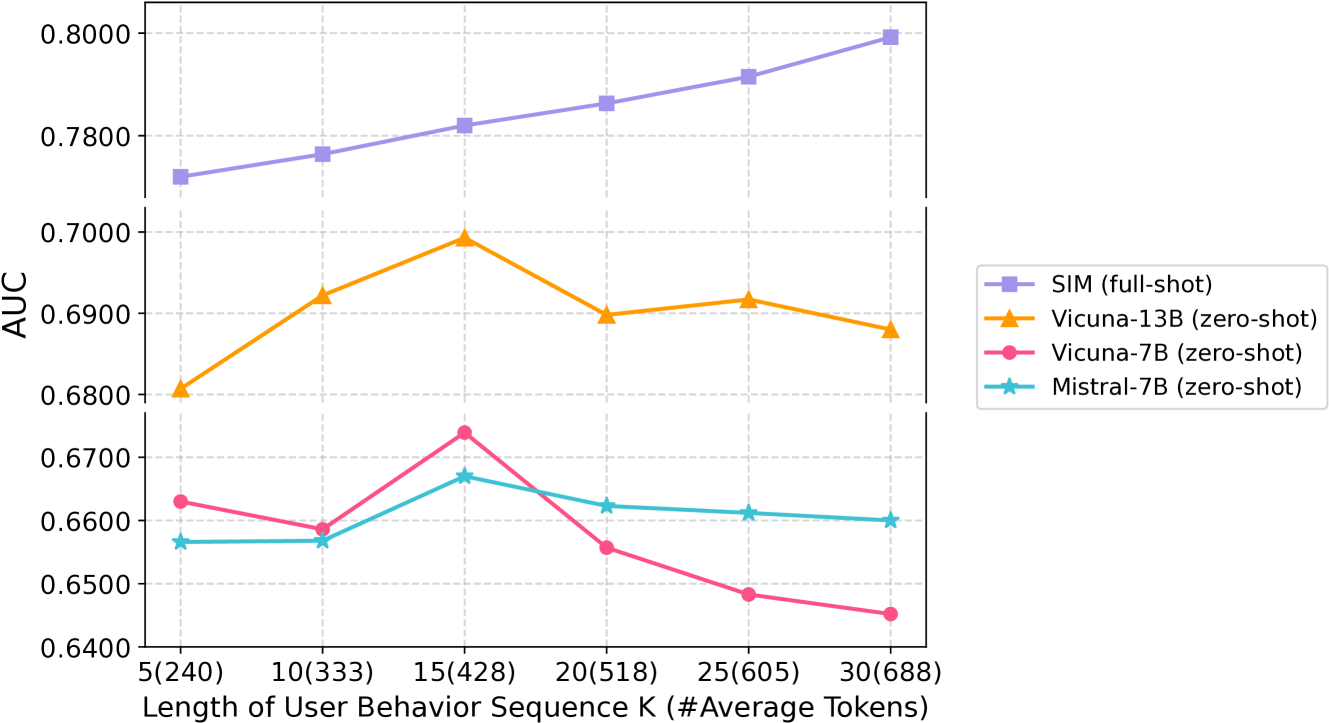
Long-sequence Modeling
ReLLaX addresses the inability of LLMs to comprehend long user behavior sequences in recommendation by optimizing data retrieval, injecting collaborative soft prompts, and enabling fully interactive parameter adaptation.
Core Problem
LLMs suffer from 'lifelong sequential behavior incomprehension,' where they fail to extract useful information from long user behavior text sequences (e.g., >15 items) even when the text fits within context limits.
Why it matters:
- Contrary to NLP tasks where LLMs handle long contexts well, their performance in recommendation peaks at short sequences and degrades as history length increases.
- Traditional truncation (keeping only recent items) discards valuable long-term user preference signals necessary for accurate prediction.
- Existing adaptations like standard LoRA lack the expressive power to capture the complex dependencies in lifelong behavioral data.
Concrete Example:
In a movie recommendation scenario, if a user watched 50 movies, a standard LLM's accuracy might peak after seeing the last 15 and drop if shown all 50. ReLLaX retrieves the most semantically relevant movies (e.g., 'Sci-Fi' genre matches) rather than just the most recent ones and formats them effectively for the LLM.
Key Novelty
Full-Stack Optimization (ReLLaX)
- Data-level: Semantic User Behavior Retrieval (SUBR) selects relevant historical items based on semantic similarity to the target, reducing sequence heterogeneity compared to chronological truncation.
- Prompt-level: Soft Prompt Augmentation (SPA) projects item embeddings from a conventional recommendation model into soft tokens, injecting collaborative filtering knowledge directly into the LLM input.
- Parameter-level: Component Fully-interactive LoRA (CFLoRA) decomposes adaptation matrices into vectors and enables full interaction between them, guided by user history, to increase expressive power.
Architecture
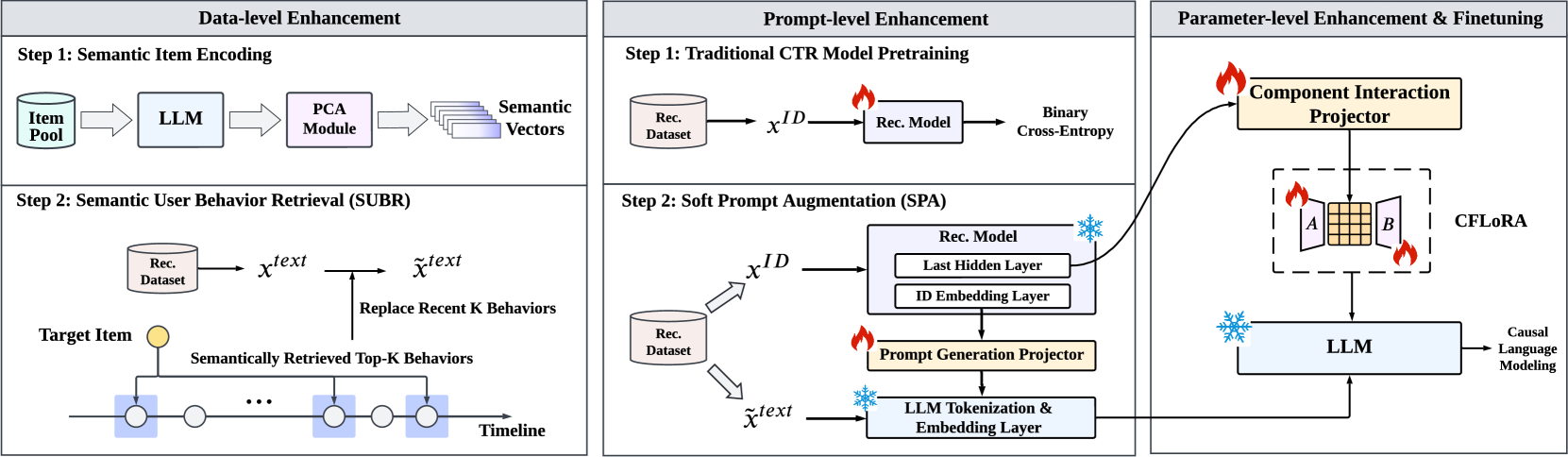
The overall architecture of ReLLaX, illustrating the three optimization levels: Data (SUBR retrieval), Prompt (text + soft tokens), and Parameter (CFLoRA adaptation).
Evaluation Highlights
- Achieves state-of-the-art performance on MovieLens-1M (AUC 0.9234), outperforming the best LLM baseline GLRec by +0.0049.
- Demonstrates consistent gains on Amazon Books (AUC 0.8932) and Amazon Electronics (AUC 0.8972) datasets compared to strong baselines like CoLLM and TallRec.
- Outperforms the conference version (ReLLa) by effectively utilizing Soft Prompt Augmentation and CFLoRA to handle longer sequences without performance degradation.
Breakthrough Assessment
7/10
Significant improvement in adapting LLMs for specific recommendation constraints (long history). Theoretically grounded modification of LoRA (CFLoRA) is a strong technical contribution beyond simple prompt engineering.