📝 Paper Summary
Conversational Recommender Systems (CRSs)
Automatic Evaluation Metrics
FACE decomposes conversations into atomic particles and evaluates them using LLM-optimized instructions to provide fine-grained, interpretable scores for conversational recommender systems without needing reference responses.
Core Problem
Existing CRS evaluation methods are either reference-based (ignoring dynamic interactions) or provide single uninterpretable scores (LLM-based), failing to diagnose specific turn-level or dialogue-level issues.
Why it matters:
- Human evaluation is too costly for intensive development cycles, creating a need for reliable automatic proxies
- Static metrics like BLEU fail to capture the validity of diverse, valid responses in open-ended conversations
- Current LLM evaluators provide 'black box' scores, making it difficult for developers to trace low scores back to specific system behaviors or failure points
Concrete Example:
A user says 'Inception seems interesting'. A traditional metric checking against a fixed reference like 'Great choice!' might penalize a system that says 'Ideally, you should watch it on a big screen,' even though the latter is a valid, engaging response. Furthermore, a standard LLM score of 3/5 doesn't explain *why* the dialogue failed (e.g., was it irrelevant or just boring?).
Key Novelty
Fine-grained Aspect-based Conversation Evaluation (FACE)
- Decomposes complex dialogues into 'conversation particles' (atomic units of Act, Mention, Feedback) to handle the one-to-many nature of valid responses
- Optimizes evaluation instructions using a 'textual gradient' approach where an LLM critiques and rewrites prompts to maximize correlation with human judgments
- Aggregates scores from atomic particles up to turn and dialogue levels, allowing humans to trace a low dialogue score back to specific problematic utterances
Architecture
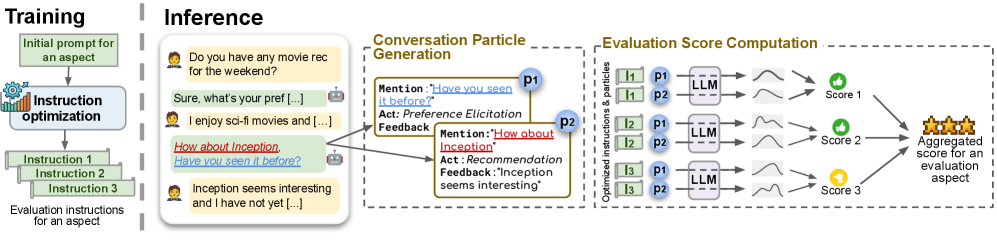
The FACE pipeline illustrating the transformation of a dialogue into particles, evaluation via optimized instructions, and aggregation into final scores.
Evaluation Highlights
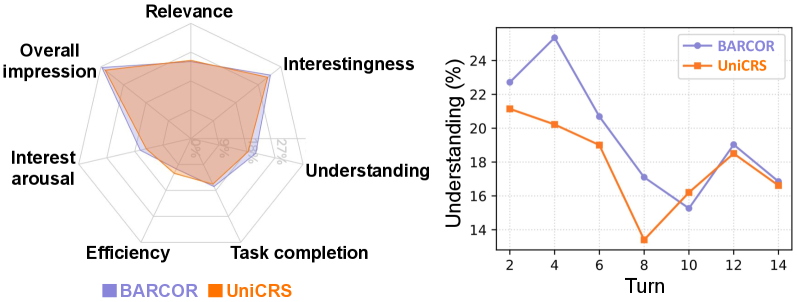
- Achieves system-level Spearman correlation of 0.9 with human judgments, significantly outperforming state-of-the-art baselines
- Achieves turn/dialogue-level Spearman correlation of 0.5 across diverse evaluation aspects
- Generalizes to unseen chatbots (Topical-Chat, PersonaChat) while maintaining strong performance without observing their data during instruction optimization
Breakthrough Assessment
8/10
Strong contribution to the difficult problem of CRS evaluation. The particle decomposition offers a novel structural solution to interpretability, and the high correlation (0.9) with human judgment is impressive.