📝 Paper Summary
Generative Recommendation
LLM Fine-tuning for Recommendation
Reinforcement Learning for Recommendation
GFlowGR models recommendation as a multi-step generative process, using GFlowNets to provide token-level supervision and align generation probabilities with item values across diverse user interactions.
Core Problem
Standard fine-tuning (SFT) for generative recommendation only learns from single positive items, ignoring negative signals and failing to provide token-level feedback during the multi-step generation process.
Why it matters:
- SFT forces models to predict only one ground truth, neglecting the rich signals available in the full set of user interactions (e.g., clicks vs. impressions).
- Current reward-based methods (like DPO) assign rewards only at the final item level, missing critical supervision for the intermediate tokens that make up an item identifier.
- Industrial systems need to generate diverse, high-value recommendations, but SFT's sequence-to-sequence objective often collapses diversity.
Concrete Example:
A user clicks a 'blue jacket' but ignores a 'yellow undershirt'. SFT trains the model only to generate the jacket's tokens. It fails to explicitly discourage the undershirt or credit the specific tokens (e.g., 'blue', 'formal') that made the jacket attractive, unlike GFlowGR which weights generation paths by value.
Key Novelty
Generative Flow Networks for Generative Recommendation (GFlowGR)
- Treats the generation of an item identifier (token sequence) as a trajectory in a flow network, where the final item's value (reward) dictates the flow (probability) of that path.
- Introduces a trajectory sampler that augments training data with negative or lower-value items (from logs or models), turning unobserved data into useful learning signals.
- Provides token-level gradients by enforcing flow balance at every step of generation, rather than just punishing the final output.
Architecture
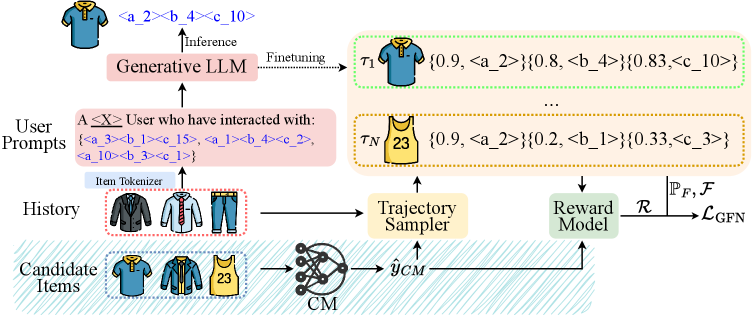
The GFlowGR training framework. It illustrates how a user prompt and item V are processed: the trajectory sampler adds augmented samples (V_n), the LLM estimates flows, and the Reward Model assigns values to update the LLM via GFlowNet loss.
Evaluation Highlights
- Achieves significant performance gains (e.g., +26.9% in NDCG@5 on MovieLens-1M) compared to standard SFT and RL baselines like DPO.
- Deployed in Taobao's production system, serving hundreds of millions of users and driving a 1% relative increase in billion-level annual advertising revenue.
- Consistently outperforms baselines across three datasets (MovieLens, Amazon Beauty, Amazon Toys) using different backbone models (T5-Base, Llama-130M).
Breakthrough Assessment
8/10
Strong industrial validation (Taobao deployment) combined with a theoretically grounded application of GFlowNets to the specific problem of token-based generative recommendation. Addresses a clear gap in granular supervision.
