📝 Paper Summary
LLM-based Ranking
Reasoning in LLMs
R1-Ranker unifies diverse ranking tasks into a single model by using reinforcement learning and an iterative elimination strategy that decomposes complex ranking into step-by-step reasoning decisions.
Core Problem
Existing LLM rankers are often domain-specific, tied to fixed backbones without post-training optimization, and struggle with the large output space required for direct listwise ranking.
Why it matters:
- Ranking tasks (recommendation, routing, retrieval) are fragmented across specialized models, limiting generalizability
- Standard LLMs are not optimized for ranking decisions during post-training, failing to exploit their full reasoning potential
- Directly generating a full ranked list overwhelms the LLM's context window and reasoning capacity, leading to suboptimal ordering
Concrete Example:
When asked to rank 20 candidates, a standard LLM often hallucinates or misses items due to the large output space. In contrast, R1-Ranker iteratively selects and removes the 'worst' candidate one by one, simplifying the task to a sequence of binary-like decisions.
Key Novelty
Unified Reasoning-Incentive Ranker (IRanker)
- Decomposes listwise ranking into an iterative elimination process: the model repeatedly identifies and removes the least relevant candidate, reversing the exclusion order to form the final rank
- Applies Reinforcement Learning (PPO) with a specific 'exclusion reward' to incentivize the model to reason about negative candidates at each step, rather than just matching a ground truth list
Architecture
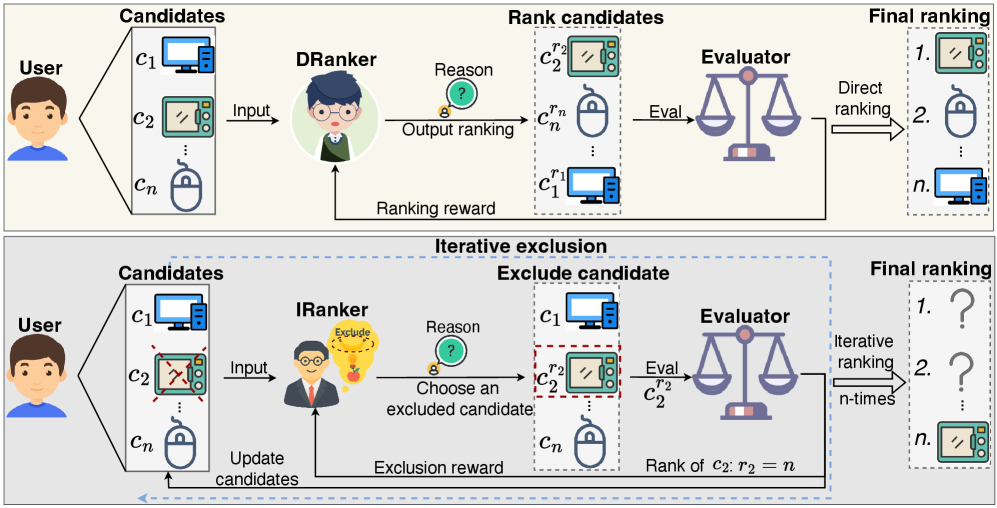
Comparison of DRanker (Direct Ranker) and IRanker (Iterative Ranker) workflows.
Evaluation Highlights
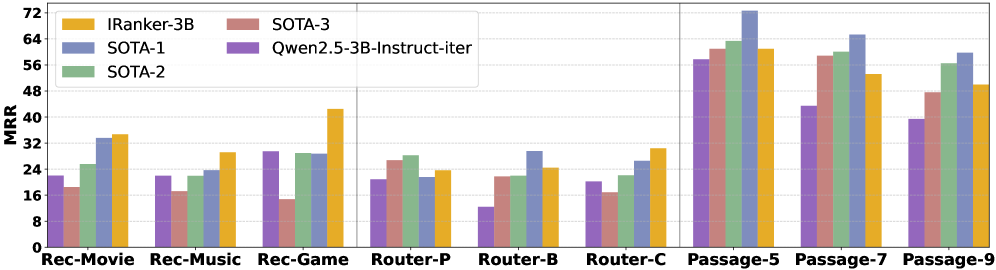
- IRanker-3B achieves a 15.7% average relative improvement over larger 7B models across nine datasets in recommendation, routing, and passage ranking
- Outperforms domain-specific SOTA methods like SASRec (recommendation) and RankLLama-8B (retrieval) using a single unified 3B model
- Zero-shot reasoning transfer: IRanker-3B improves by over 9% on out-of-domain reasoning tasks like GSM8K and MathQA compared to the base model
Breakthrough Assessment
9/10
Successfully unifies three distinct ranking domains with a single small (3B) model that beats specialized baselines. The iterative elimination strategy is a clever architectural shift for LLM ranking.