📝 Paper Summary
LLM-enhanced Recommender Systems
Sample Efficiency in Recommendation
Laser demonstrates that LLMs can function as highly sample-efficient recommenders themselves or enhance conventional models by generating user/item knowledge that compensates for data sparsity.
Core Problem
Conventional recommendation models (CRMs) suffer from sample inefficiency, requiring massive amounts of interaction data to learn effective ID-based representations due to feature sparsity.
Why it matters:
- Data sparsity remains a critical bottleneck in recommender systems, making it difficult to train effective models for new users or items with few interactions (cold start)
- Collecting and annotating large-scale recommendation datasets is resource-intensive and costly
- Existing methods relying on ID embeddings struggle to generalize when labeled data is scarce
Concrete Example:
A standard CRM like DeepFM fails to predict user clicks accurately when trained on only 10% of the data because ID embeddings are under-trained. Laser compensates by using an LLM to generate text-based user profiles and item descriptions, providing rich semantic features even with minimal interaction history.
Key Novelty
Laser Framework (LLM-Enhanced Sample Efficiency)
- Validates that LLMs themselves are inherently sample-efficient recommenders capable of few-shot preference inference using open-world knowledge
- Proposes a hybrid paradigm where LLMs generate textual user/item knowledge that is encoded via Mixture-of-Experts (MoE) adapters to augment conventional ID-based models
Architecture
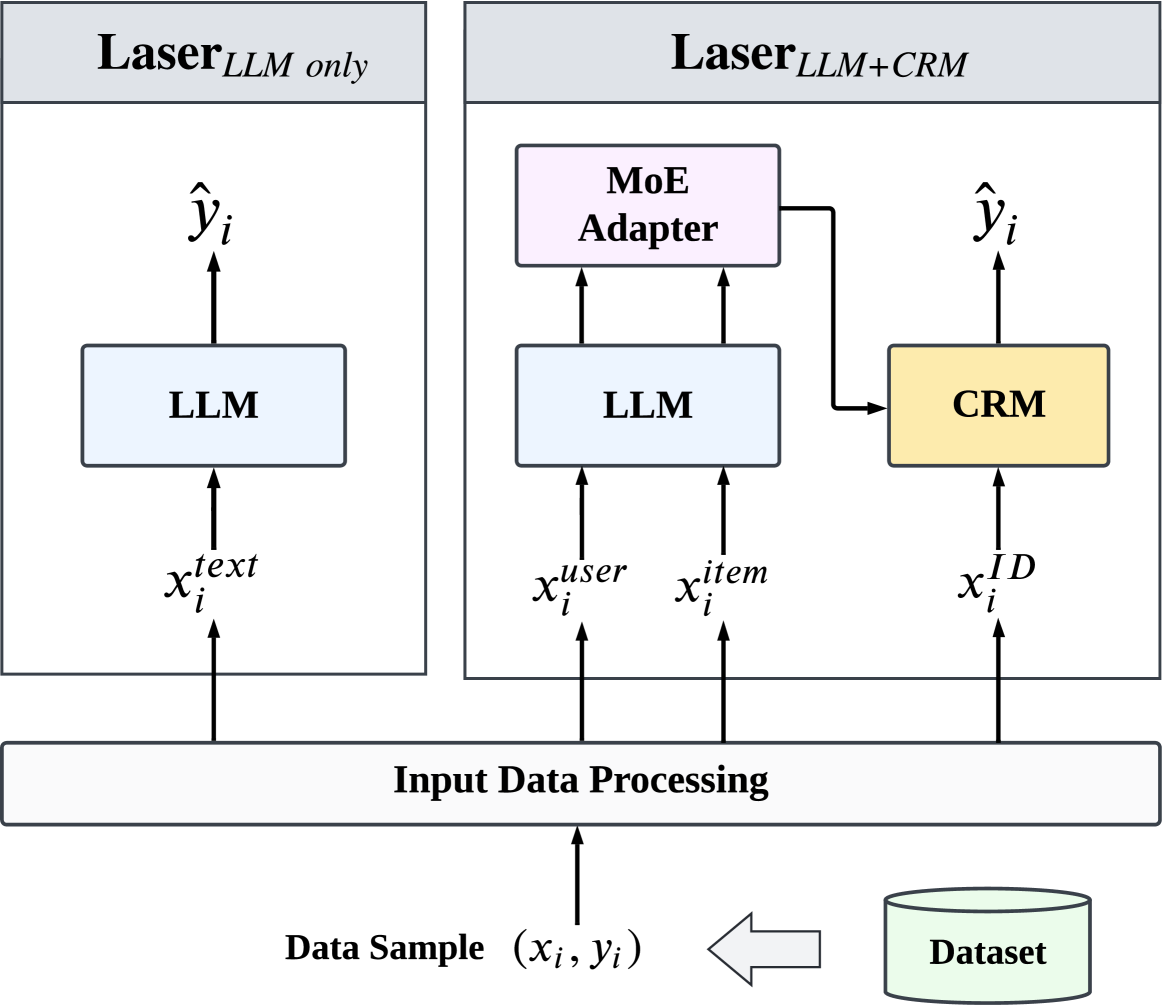
The overall framework of Laser illustrating two paradigms: Laser (LLM only) and Laser (LLM+CRM).
Evaluation Highlights
- Laser (LLM only) matches or surpasses conventional models trained on the *entire* dataset while using only 10% of the training samples
- Laser (LLM+CRM) matches full-dataset baselines using only 50% of the training data
- Demonstrates superior sample efficiency on both BookCrossing and MovieLens-1M datasets compared to strong baselines like SIM and DIN
Breakthrough Assessment
7/10
Systematically quantifies the sample efficiency benefits of LLMs in recommendation. While the methods (LLM-as-recommender, LLM-as-feature-encoder) are known, the specific focus on sample efficiency and the hybrid MoE integration offers a solid empirical contribution.