📝 Paper Summary
Course Recommender Systems
Educational Technology
Applications of LLMs in Education
RAMO integrates Retrieval-Augmented Generation with LLMs to provide personalized course recommendations for new users without historical data, overcoming the cold start problem inherent in traditional collaborative filtering.
Core Problem
Traditional course recommender systems (like collaborative filtering) fail to provide suggestions for new users because they rely on historical data that does not exist for new accounts.
Why it matters:
- Students are overwhelmed by the vast selection of MOOCs and need guidance when exploring new fields
- New users ("cold start") receive no recommendations or generic ones, leading to potential disengagement
- Standard LLMs can hallucinate non-existent courses or provide outdated information when asked for recommendations
Concrete Example:
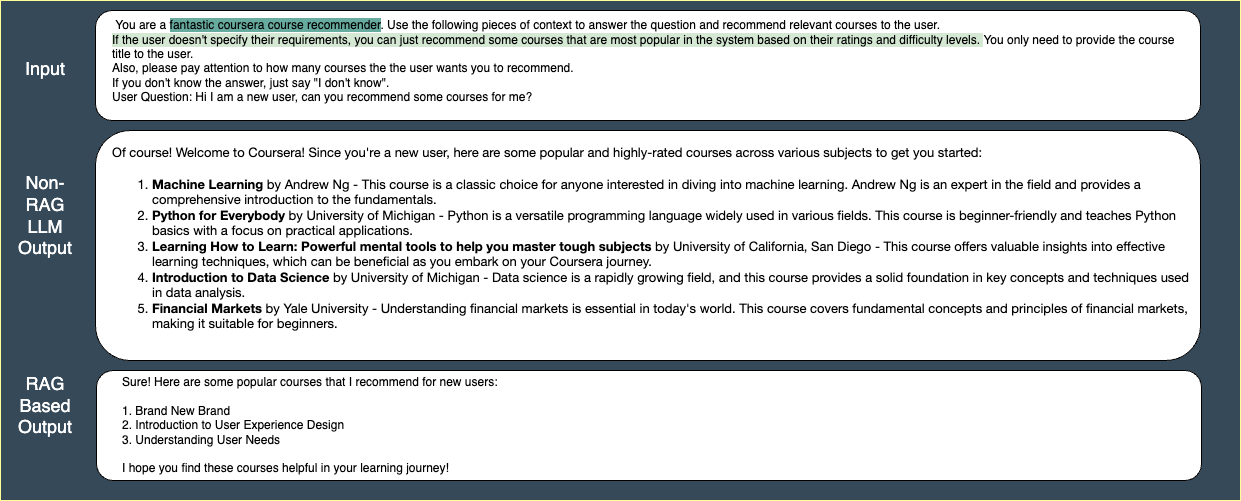
When a new user asks 'I am a new user', a traditional collaborative filtering system generates no output because it relies on cosine similarity of user history. RAMO, however, utilizes a prompt template to suggest introductory courses immediately.
Key Novelty
RAMO (Retrieval-Augmented Generation for MOOCs)
- Combines LLM generation with a retriever grounded in a specific Coursera dataset to ensure course existence
- Utilizes a 'prompt template' strategy to handle queries with zero user history
- Injects 'emotional intelligence' into prompts (e.g., using the word 'fantastic') to shape the tone of the LLM's response
Architecture
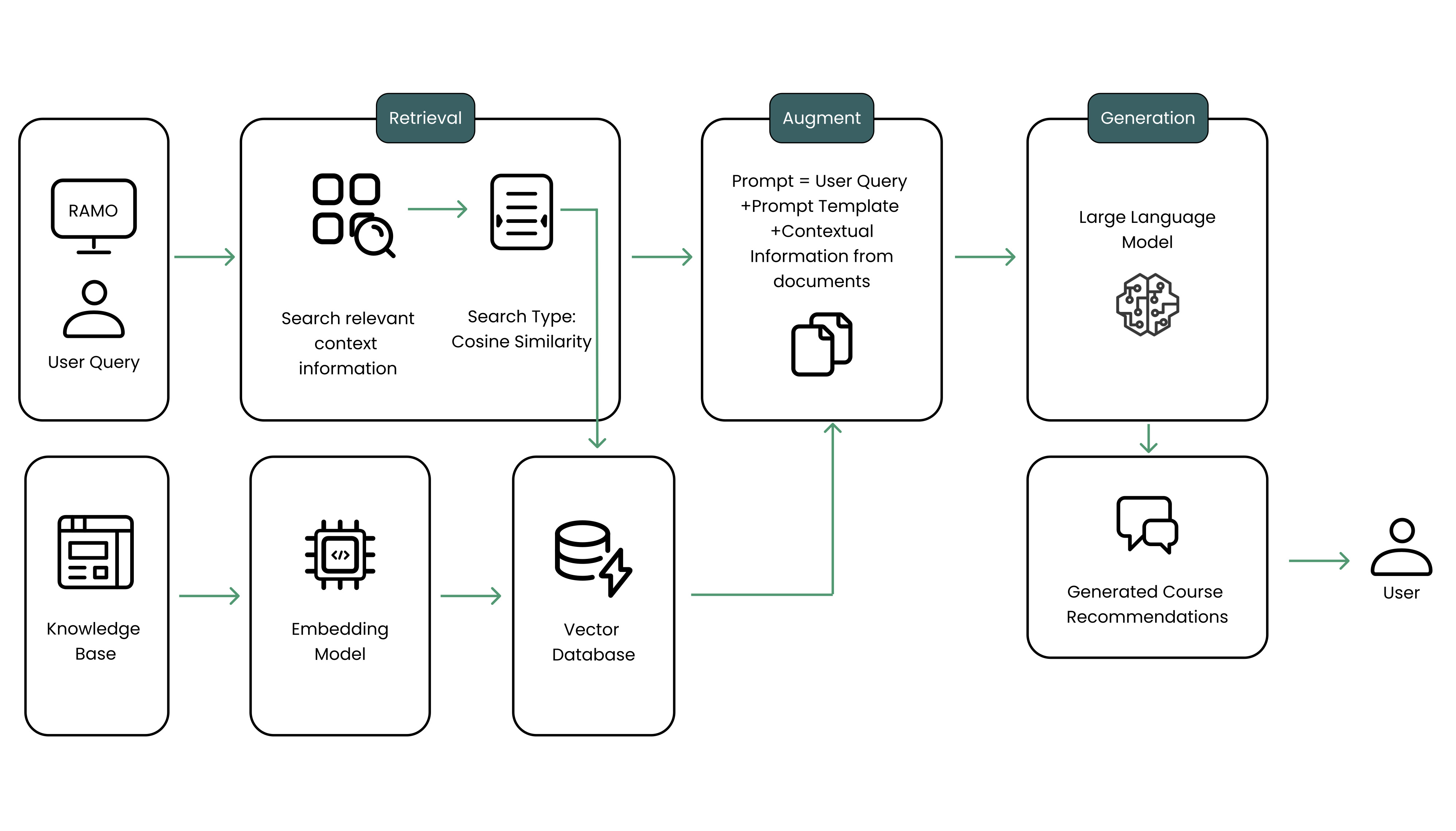
The workflow of the RAG facilitated course recommendation system (RAMO)
Evaluation Highlights
- Successfully generates relevant course recommendations for 'cold start' queries where traditional baselines failed completely
- RAMO generated responses approximately 0.02 seconds faster than the traditional baseline system according to the author's measurements
- Demonstrates capability to filter and recommend from a database of 3,342 courses using natural language queries
Breakthrough Assessment
4/10
Applies established RAG techniques to a specific domain (MOOCs). While it effectively addresses the cold start problem application-wise, the architectural novelty is limited to standard RAG implementation details.