📝 Paper Summary
Video Recommendation
Multimodal Representation Learning
LinkedOut extracts and fuses internal token representations from multiple layers of a video LLM to create dense, world-knowledge-aware embeddings for recommendation without the latency of text generation.
Core Problem
Video Large Language Models (VLLMs) contain valuable world knowledge but are impractical for recommendation due to slow sequential decoding, inability to handle multi-video histories, and text outputs that discard fine-grained visual details.
Why it matters:
- Current production systems rely on hand-crafted tags or IDs, discarding pixel-level information and limiting personalization in cold-start scenarios
- Pipelines that summarize videos into text first (the 'language bottleneck') lose nuanced visual attributes like narrative pacing or humor
- Deploying full VLLMs for real-time ranking is computationally prohibitive due to latency requirements and high token costs for user history
Concrete Example:
A standard VLLM might summarize a video as 'a funny cat clip,' losing the specific visual style or pacing needed to recommend similar content. Furthermore, feeding a user's 50-video history into a VLLM for real-time ranking would exceed context limits and take too long to process.
Key Novelty
Cross-Layer Knowledge-Fusion Mixture-of-Experts
- Instead of using the final text output or just the last layer, the system extracts 'thought vectors' (hidden states) from multiple depths of the VLLM backbone
- A Mixture-of-Experts (MoE) module dynamically learns which layer's abstraction level (low-level visual vs. high-level semantic) is most relevant for representing a specific video item
Architecture
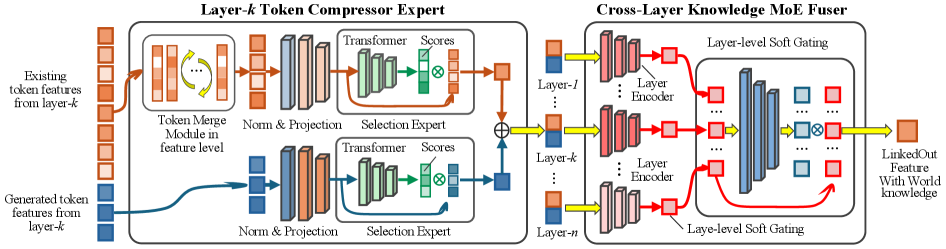
The core LinkedOut representation module, showing how tokens are extracted and fused.
Breakthrough Assessment
7/10
Proposes a significant architectural shift by treating VLLMs as multi-level feature mines rather than text generators, addressing the critical latency/granularity trade-off in multimodal RecSys.