📝 Paper Summary
Explainable Recommendation
LLM-based Recommendation
RecExplainer fine-tunes large language models to act as surrogate explainers by aligning them with target recommendation models through behavior mimicry and latent space comprehension.
Core Problem
Embedding-based recommender systems are effective but operate as black boxes, lacking transparency and interpretability for users and developers.
Why it matters:
- Traditional surrogate models (like decision trees) sacrifice fidelity for interpretability, while complex models lack human-readable explanations
- Existing explanations are often limited to simple weights or rules, missing semantic, human-readable reasoning
Concrete Example:
A traditional recommender suggests a movie based on latent vectors, but cannot explain *why*. RecExplainer allows an LLM to output: 'I recommend this movie because it aligns with your interest in Sci-Fi shown by your history of watching Star Wars.'
Key Novelty
RecExplainer (Three Alignment Strategies)
- Behavior Alignment: Fine-tunes the LLM to predict the target model's output (items) given textual user history, mimicking the target's external behavior
- Intention Alignment: Injects the target model's internal user/item embeddings directly into the LLM's input space, treating embeddings as a new language modality
- Hybrid Alignment: Combines both textual history and latent embeddings to reduce hallucination and improve fidelity
Architecture
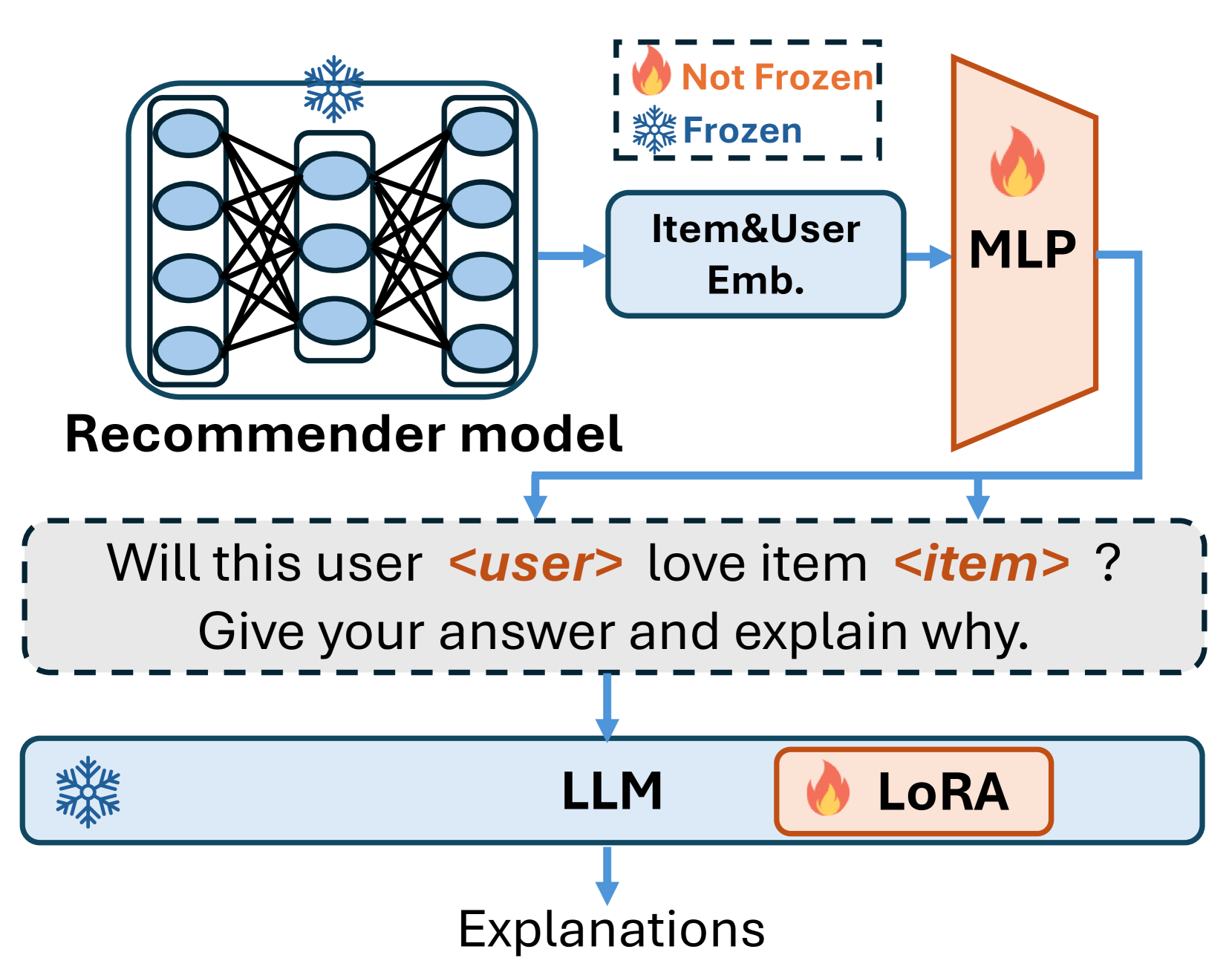
The model architecture for Intention Alignment. It illustrates how user/item embeddings from the frozen target model are projected via a linear layer into the LLM's input space.
Evaluation Highlights
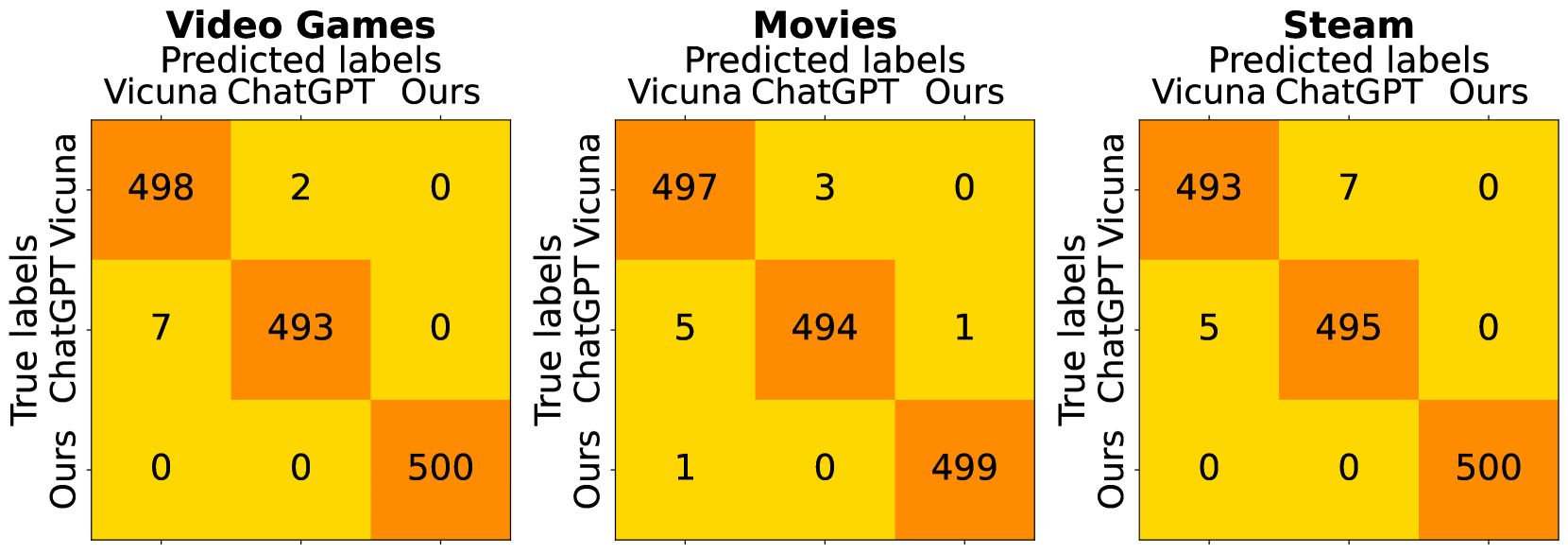
- Hybrid alignment achieves significantly better alignment accuracy (Acc@1) than standard LLM prompting (e.g., 29.8% vs ~3% on Amazon Beauty)
- Explanations generated by the aligned LLM are rated higher by humans and GPT-4 for helpfulness and clarity compared to baselines
- Intention alignment proves more effective than behavior alignment for pure recommendation tasks, but hybrid alignment balances generation quality best
Breakthrough Assessment
7/10
Novel application of LLMs as surrogate models using embedding alignment. Strong empirical results on alignment, though primarily an integration of existing techniques (LLM tuning + projection layers).