📝 Paper Summary
Recommender Systems
AI-Generated Content (AIGC) Bias
Feedback Loops
Sequential recommender systems inherently rank LLM-generated text higher than human text, creating a feedback loop that progressively amplifies this bias and eventually degrades recommendation performance.
Core Problem
As AI-Generated Content (AIGC) floods the internet, recommender systems exhibit 'Source Bias,' preferentially ranking AIGC higher than human content. This bias creates a self-reinforcing feedback loop.
Why it matters:
- Unfairness: Content creators may be forced to use LLMs to rewrite descriptions just to gain visibility, disadvantaging original human writing
- Model Collapse: Training on excessive AIGC (which models prefer) eventually leads to a decline in recommendation accuracy and ecosystem diversity
- Traffic Distribution: The bias causes unfair traffic allocation, pushing AIGC to the top regardless of actual user preference or utility
Concrete Example:
A human seller writes a product description. An LLM rewrites it to be semantically identical but stylistically different. The recommender system ranks the LLM version higher solely due to its source style, pushing the human version down the list.
Key Novelty
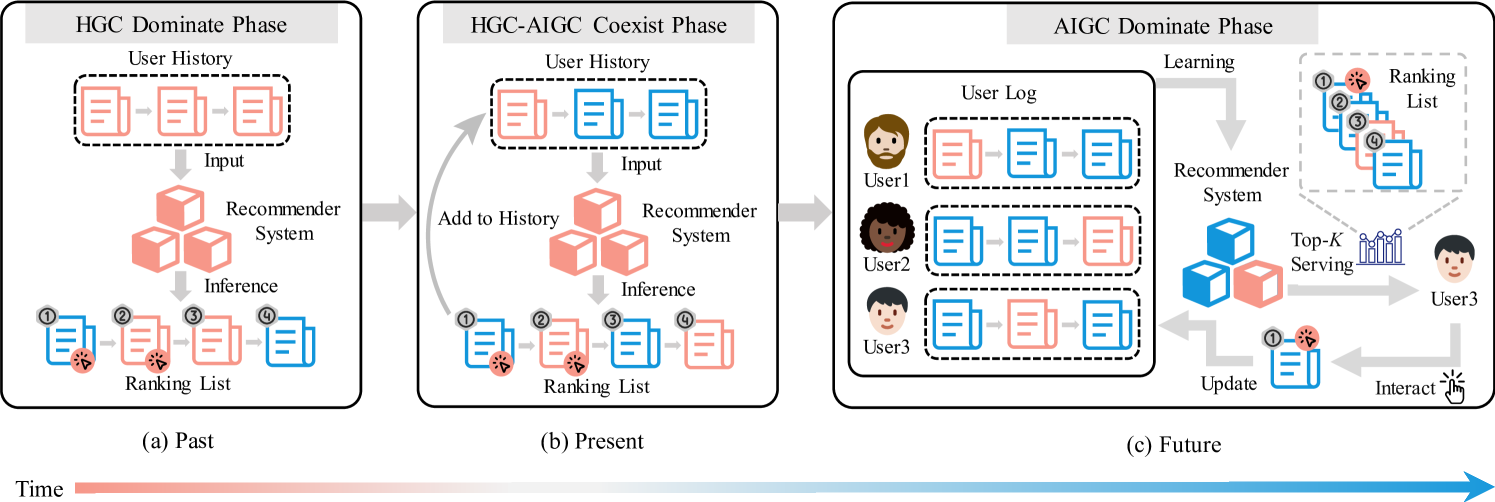
Simulation of AIGC Escalation in Feedback Loops
- Identifies 'Source Bias' where models favor LLM-generated text patterns (e.g., from Llama or Mistral) over human text
- Simulates a three-phase evolution (HGC Dominate → Coexist → AIGC Dominate) to show how user interactions and retraining amplify this initial bias over time
- Proposes a debiasing method using L1-loss optimization to align the embedding spaces of human and AI-generated content
Architecture
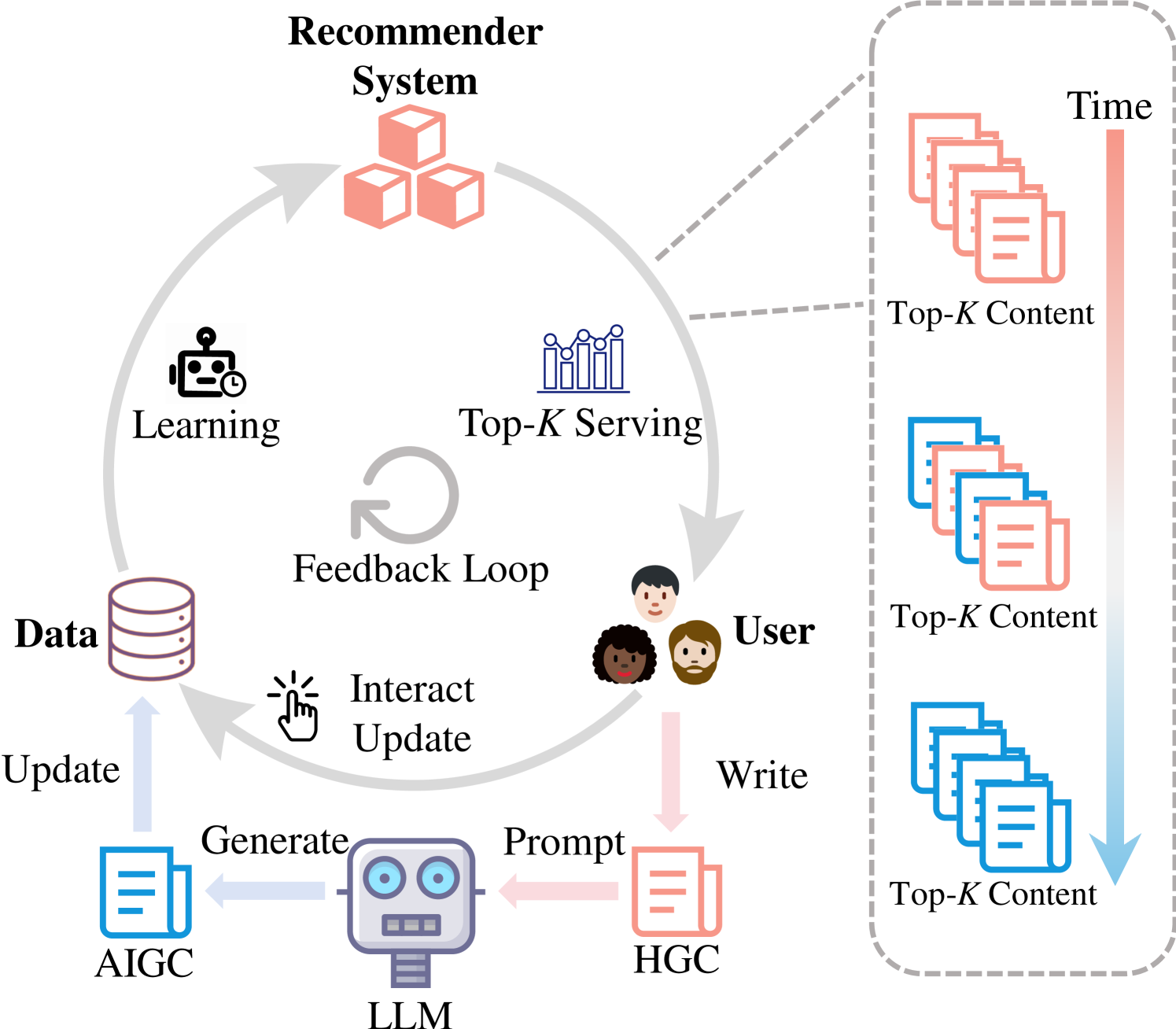
The Feedback Loop involving Users, Data, and the Recommender System
Evaluation Highlights
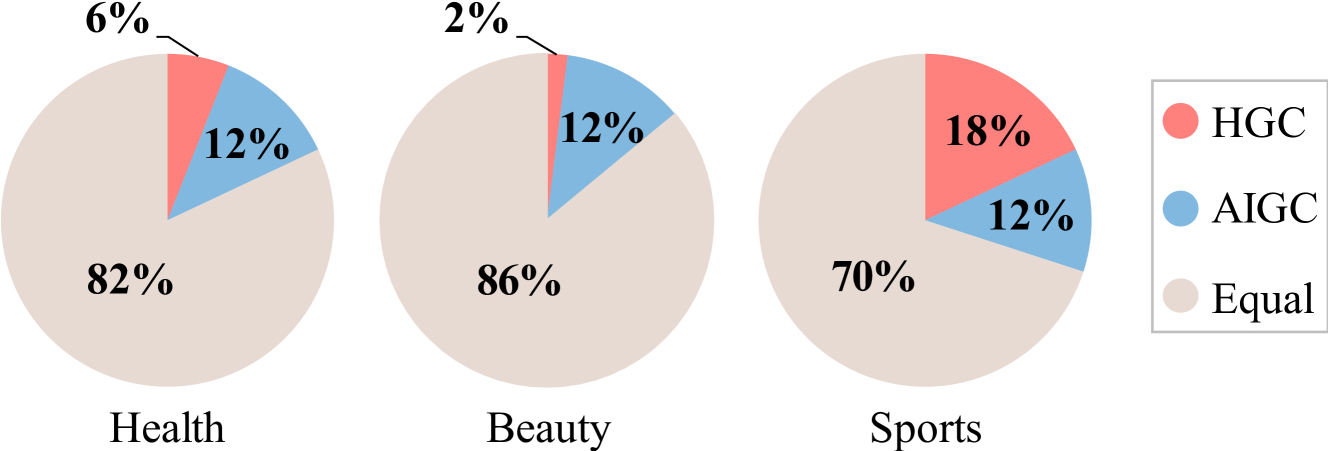
- Demonstrates that popular sequential models (BERT4Rec, SASRec) rank AIGC copies higher than original human text across Amazon datasets (Health, Beauty, Sports)
- Shows that ChatGPT-generated content induces less bias compared to other LLMs (Llama, Mistral), likely due to alignment training
- Experiments reveal a decline in recommendation performance (NDCG/MAP) after AIGC dominates the feedback loop (20 iterations)
Breakthrough Assessment
7/10
Important identification of a subtle but systemic bias (Source Bias) in the LLM era. The simulation of feedback loops provides a necessary long-term view of AIGC's impact on RecSys, though the solution (L1 loss) is relatively standard.