📝 Paper Summary
LLM-based Recommender Systems
Generative Recommendation
CLLM4Rec extends pretrained LLMs with dedicated user/item ID tokens learned via a novel soft+hard prompting strategy to bridge the gap between natural language and collaborative semantics.
Core Problem
Existing LLM-based recommenders struggle with the semantic gap between natural language and recommendation tasks, leading to spurious correlations from pseudo-IDs, ineffective language modeling on heterogeneous tokens, and inefficient auto-regressive inference.
Why it matters:
- Pseudo-ID methods (e.g., 'user_432') break into meaningless sub-tokens, causing spurious correlations between unrelated users
- Description-based methods (e.g., item titles) introduce strong inductive biases that may not capture true collaborative signals
- Standard auto-regressive generation is inefficient for ranking large candidate pools and prone to hallucination if candidates aren't explicitly provided
Concrete Example:
Representing a user as 'user_4332' might be tokenized into ['user', '_', '43', '32'], causing the model to spuriously correlate them with 'user_43' or 'user_32', even if those users have nothing in common.
Key Novelty
Collaborative LLM for Recommender Systems (CLLM4Rec)
- Extends the LLM vocabulary with specific user/item ID tokens to capture collaborative semantics, rather than relying on textual descriptions or pseudo-IDs
- Uses a 'soft+hard' prompting strategy where documents are split into a heterogeneous prompt (user/item tokens + vocab) and a homogeneous main text (vocab only or item tokens only) to stabilize training
- Employs a mutual regularization strategy where collaborative and content-based LLMs share user/item embeddings to enforce semantic alignment
Architecture
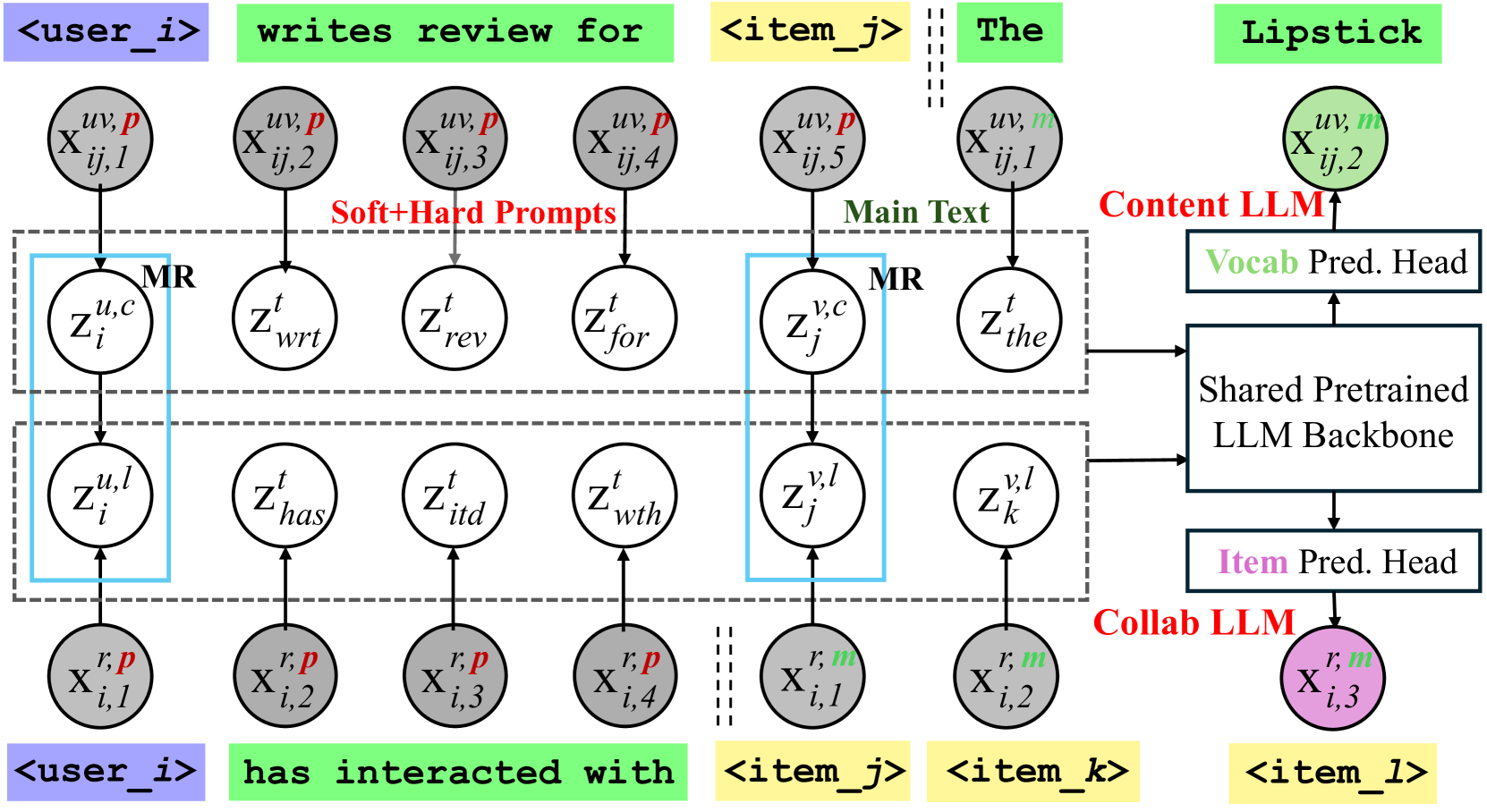
The overall framework of CLLM4Rec, detailing the vocabulary expansion, soft+hard prompting, and the dual-branch training objectives (Collaborative LLM and Content LLM).
Evaluation Highlights
- Outperforms state-of-the-art baselines like TALLRec and various ID-based methods on Beauty and Yelp datasets.
- Achieves efficient inference by using a multinomial prediction head rather than auto-regressive text generation for recommendations.
- Demonstrates effective handling of sparse data through the mutual regularization of content and collaborative signals.
Breakthrough Assessment
8/10
Significantly advances LLM-based recommendation by solving the tokenization/ID issue fundamentally. It proposes a robust way to integrate collaborative signals directly into the LLM vocabulary.