📝 Paper Summary
Session-based Recommendation (SBR)
LLM-based Recommendation
Re2LLM guides frozen LLMs to generate their own error-correction hints via self-reflection, then trains a lightweight agent to retrieve these hints for future sessions using reinforcement learning.
Core Problem
Existing LLM recommendation methods struggle to align general knowledge with specific tasks: prompt engineering lacks task-specific feedback, while fine-tuning is computationally expensive and requires open-source backbones.
Why it matters:
- Prompt-based methods often fail to elicit correct reasoning because manual prompts may not align with how LLMs understand recommendation tasks.
- Fine-tuning large models suffers from high costs, potential catastrophic forgetting, and isn't feasible for closed-source models like GPT-4.
- Anonymous sessions in SBR have scarce interactions, making accurate prediction difficult without effectively leveraging specialized knowledge.
Concrete Example:
An LLM might recommend 'Batman' after 'Casino Royale' assuming a generic action preference. However, the user might prefer spy movies specifically. Standard prompts miss this nuance, and the LLM repeats the error because it lacks feedback on why 'Batman' was wrong.
Key Novelty
Reflective Reinforcement Large Language Model (Re2LLM)
- Reflective Exploration: Instead of human-written rules, the LLM analyzes its own mistakes on training data to generate 'hints' (specialized knowledge) that fix those specific errors.
- Reinforcement Utilization: A lightweight retrieval agent is trained via RL to pick the best 'hint' for a new session, treating the frozen LLM as an environment that provides rewards (correct/incorrect predictions).
Architecture
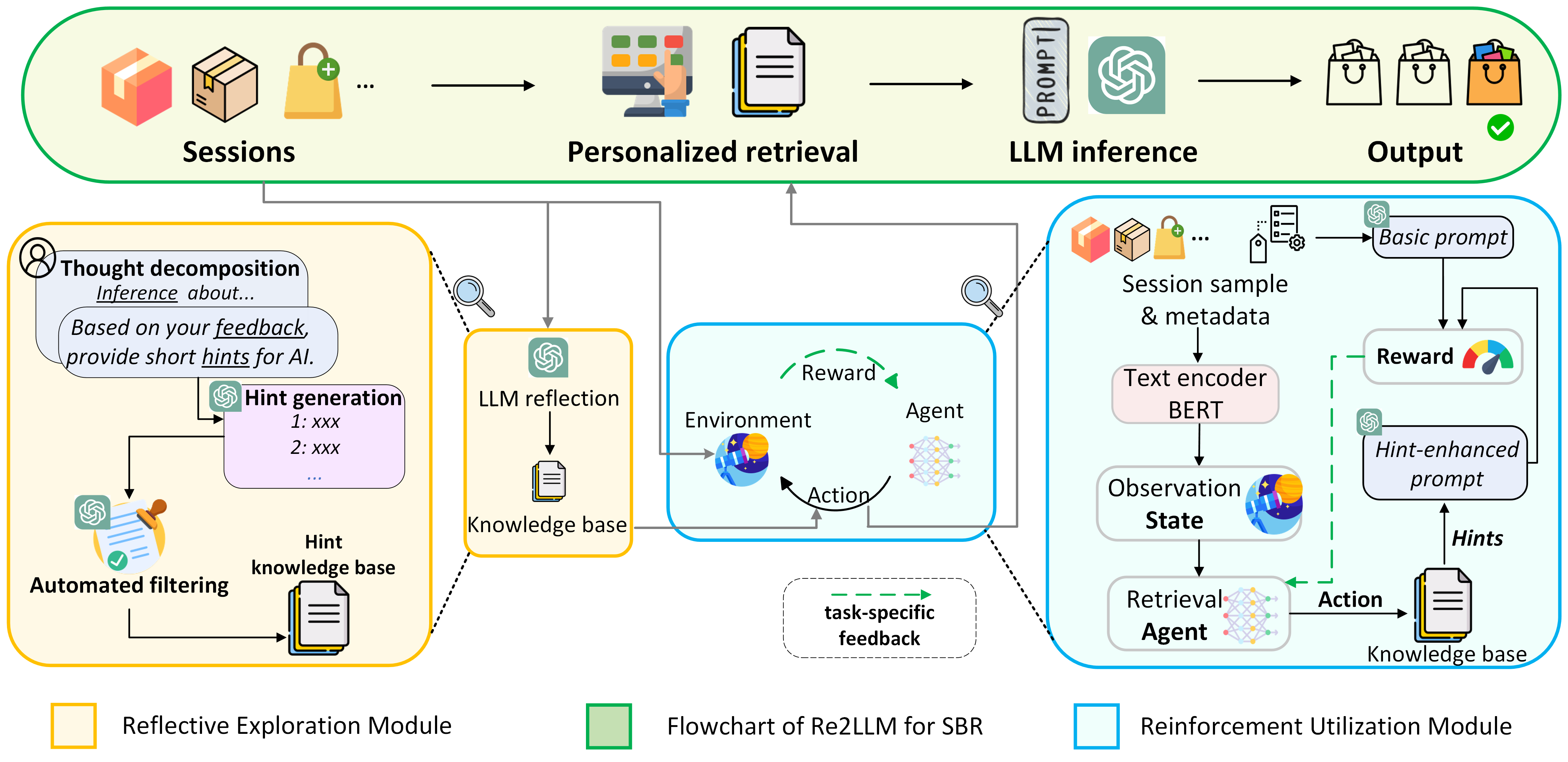
The overall architecture of Re2LLM, showing the two-stage process: constructing the Hint Knowledge Base via self-reflection, and then training the Retrieval Agent via Reinforcement Learning.
Evaluation Highlights
- Outperforms state-of-the-art methods (including fine-tuned LLaMA-7B) on MovieLens-1M and Steam datasets in both few-shot and full-data settings.
- Achieves higher NDCG@10 than the best baseline (TALLRec) on MovieLens-1M (Full) with significantly lower training costs.
- Demonstrates that self-generated hints retrieved by an RL agent are more effective than generic prompt engineering or standard retrieval augmentation.
Breakthrough Assessment
7/10
Novel combination of self-reflection for knowledge generation and RL for retrieval, effectively bridging the gap between frozen LLMs and task-specific needs without fine-tuning the heavy backbone.