📝 Paper Summary
Adversarial Attacks on Recommender Systems
LLM-based User Simulation
Agent4SR employs LLM-based agents to simulate realistic user behaviors (rating and reviewing) to successfully attack recommender systems with minimal knowledge of system internals.
Core Problem
Traditional shilling attacks rely on rigid heuristics or require inaccessible internal system data, making them easy to detect or hard to deploy, while often neglecting the impact of textual reviews.
Why it matters:
- Recommender systems drive revenue and exposure; manipulating them hurts fairness and trust
- Existing rule-based fake profiles lack behavioral diversity and are easily flagged by anomaly detection
- GAN-based methods require internal training data (rating matrices) that real-world attackers rarely possess
Concrete Example:
In a standard push attack, a heuristic method might just assign maximum ratings to a target item and random ratings to others. This creates a statistical anomaly (e.g., a 'block' in the rating matrix) that detection algorithms easily spot. Agent4SR instead generates a coherent persona that buys filler items logically and writes plausible reviews, blending in while still boosting the target.
Key Novelty
Agent4SR (Agent for Shilling Recommendation)
- Models fake users as autonomous LLM agents with distinct personality traits derived from the target item, rather than just rows in a matrix
- Uses a target feature propagation strategy in reviews: the agent subtly mentions the target item's key features (e.g., 'great battery life') in reviews for *other* unrelated products to prime the system's semantic understanding
- Operates in a low-knowledge setting, requiring no access to the target system's training data or model weights
Architecture
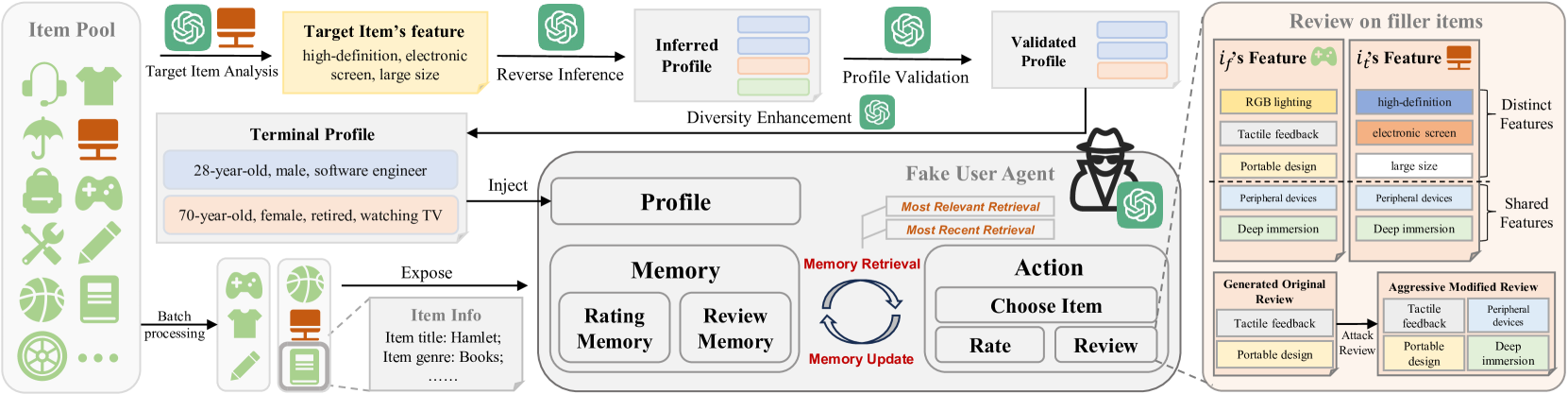
The overall framework of Agent4SR.
Evaluation Highlights
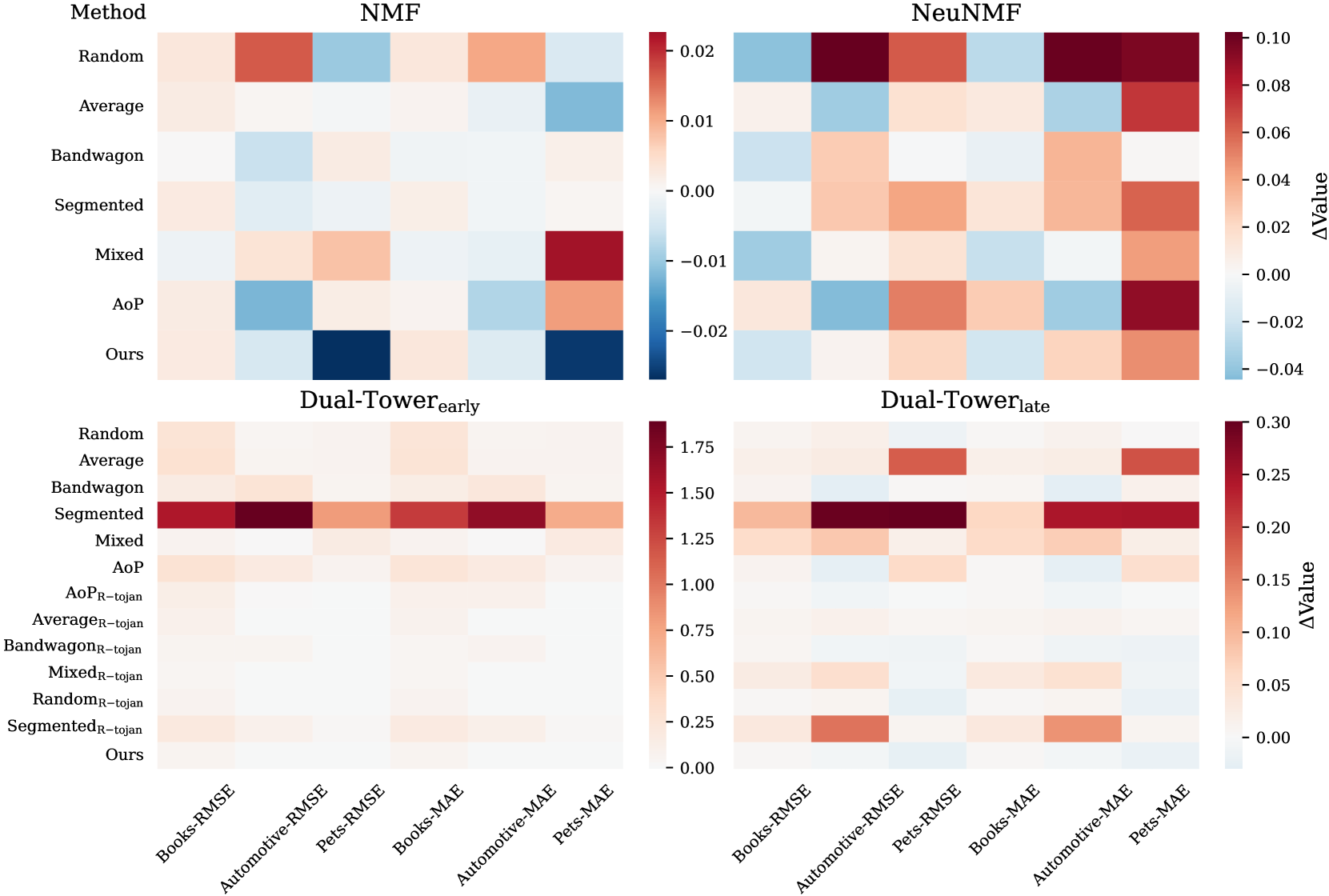
- Outperforms baseline low-knowledge attacks (e.g., Random, Bandwagon) on HR@10 and NDCG@10 across three datasets (Beauty, Toys, Sports)
- Maintains high attack effectiveness even when faced with defense mechanisms, degrading less than heuristic baselines
- Achieves higher stealth scores (lower detection rates) compared to rule-based attacks due to semantically consistent reviews and realistic rating distributions
Breakthrough Assessment
7/10
Novel application of LLM agents for adversarial purposes in RS. Moves beyond rating-only attacks to include semantic manipulation via reviews, highlighting a new class of security risks.