📝 Paper Summary
Medication Recommendation
Knowledge Distillation
Healthcare AI
LEADER adapts an LLM for medication recommendation using a classification head, then distills its semantic knowledge into a lightweight student model to handle cold-start patients and reduce inference costs.
Core Problem
Existing medication recommendation models rely heavily on patient history (failing for new patients) and use non-semantic ID codes, while direct LLM application suffers from hallucinations ('out-of-corpus' drugs) and prohibitive inference costs.
Why it matters:
- Single-visit (first-time) patients are common in healthcare but are unsupported by history-dependent models like REFINE or MICRON
- Deploying massive LLMs in hospitals is impractical due to high latency, hardware costs, and privacy concerns requiring on-premise solutions
- Standard models miss crucial medical semantics (e.g., drug interactions implied by names) by treating medications as arbitrary IDs
Concrete Example:
A first-time hospital visitor with 'Aortic valve disorder' has no prescription history. A history-based model (e.g., MICRON) cannot generate a recommendation. A raw LLM might suggest 'Aspirin-Plus' (a non-existent drug name). LEADER uses the LLM's semantic understanding to identify the correct drug, then distills this into a small model that predicts the valid drug ID.
Key Novelty
LargE languAge moDel distilling mEdication Recommendation (LEADER)
- Modifies the LLM architecture by replacing the token generation head with a classification layer, forcing the LLM to output probabilities for valid drug IDs instead of free text
- Transfers knowledge to a compact student model via feature-level distillation, projecting the student's latent representations to align with the LLM's semantically rich hidden states
- Uses contrastive profile alignment to treat patient demographics (age, gender) as a pseudo-medical record, enabling effective recommendations for patients with no prior visit history
Architecture
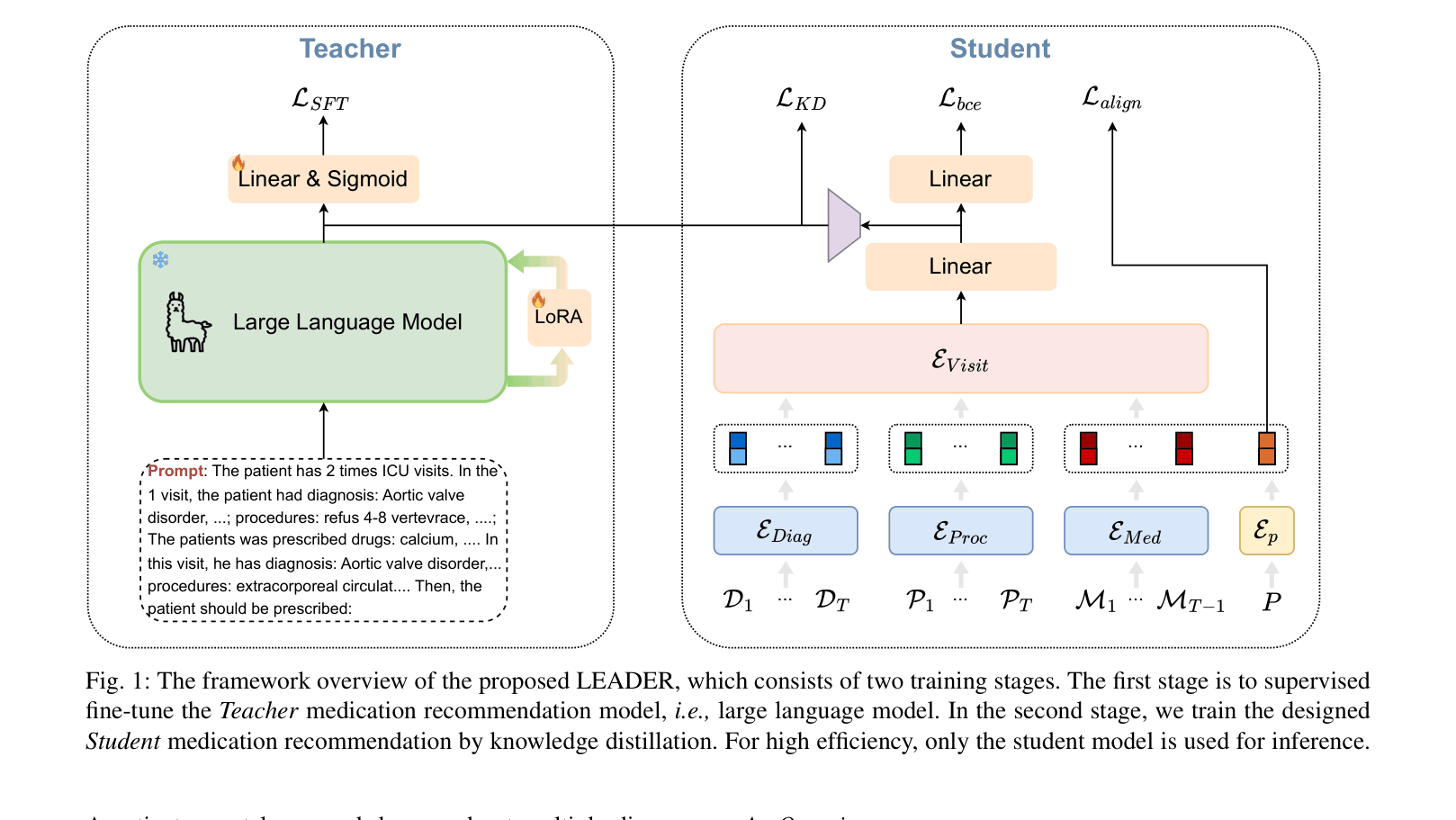
The LEADER framework showing the two-stage process: Teacher fine-tuning and Student distillation.
Evaluation Highlights
- LEADER(T) (Teacher) outperforms best baseline (E4SRec) by +2.97% PRAUC on MIMIC-IV overall, validating the semantic power of the adapted LLM
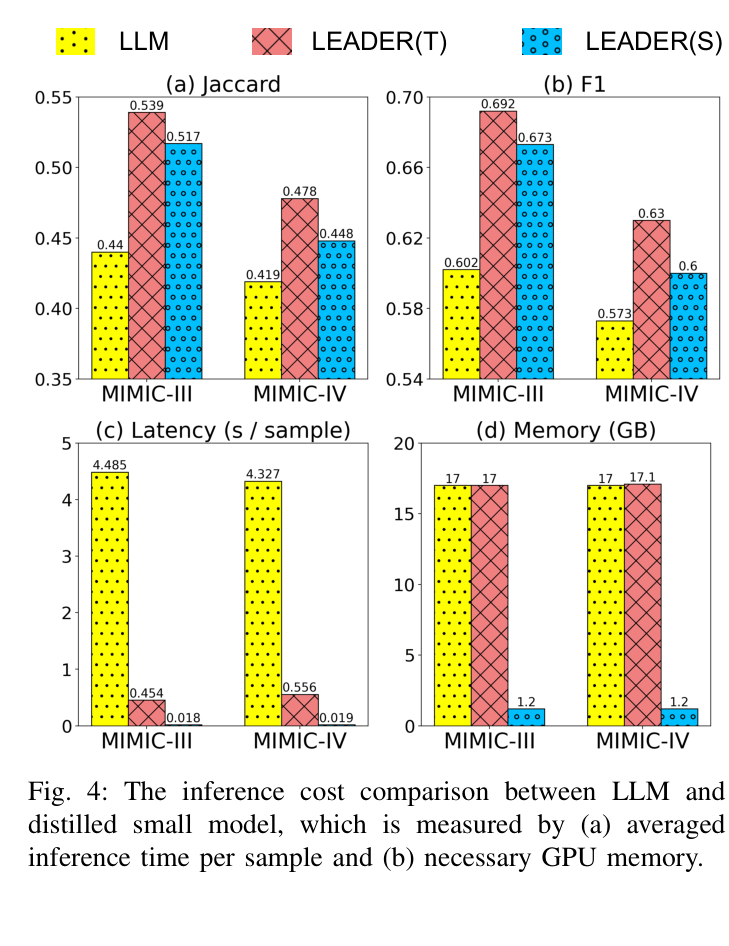
- LEADER(S) (Student) achieves 25×–30× faster inference speed and uses ~1/15th the GPU memory compared to the LLM-based teacher
- LEADER(S) surpasses the best baseline (BIGRec) by +1.1% PRAUC for single-visit (cold-start) patients on MIMIC-III, demonstrating effective knowledge transfer
Breakthrough Assessment
8/10
Successfully bridges the gap between LLM semantic capabilities and the strict constraints of healthcare (valid outputs, efficiency, cold-start). The feature-level distillation for this domain is a strong practical contribution.