📝 Paper Summary
LLM for Recommendation (LLM4Rec)
Reinforcement Learning for Recommendation
Rec-R1 optimizes LLMs for recommendation tasks via reinforcement learning using direct feedback from downstream black-box recommenders, bypassing the need for supervised fine-tuning data.
Core Problem
LLMs in recommendation systems are typically frozen or fine-tuned on proxy tasks (like mimicking GPT-4), creating a disconnect between the generation objective and actual recommendation performance.
Why it matters:
- Supervised Fine-Tuning (SFT) is constrained by the quality of teacher models (e.g., GPT-4o), imposing a performance ceiling
- Proxy objectives (like next-token prediction) do not align with downstream metrics like NDCG or Recall
- Generating high-quality SFT data is expensive and time-consuming, often requiring human annotation or commercial APIs
Concrete Example:
In product search, an SFT model might rewrite a query to sound natural (mimicking GPT-4), but the rewritten query might fail to retrieve relevant items because the downstream retriever (e.g., BM25) responds better to keyword-heavy queries. Rec-R1 learns to generate the keyword-heavy query because it optimizes for the retrieval score directly.
Key Novelty
Closed-loop RL for RecSys-LLM Alignment
- Treats the LLM as a policy that generates inputs (rewritten queries, profiles, rankings) for a fixed, black-box recommendation system
- Uses the recommendation system's output metrics (NDCG, Recall) directly as reward signals for reinforcement learning
- Optimizes the LLM to maximize these rewards via Group Relative Policy Optimization (GRPO), aligning generation with recommendation utility rather than linguistic plausibility
Architecture
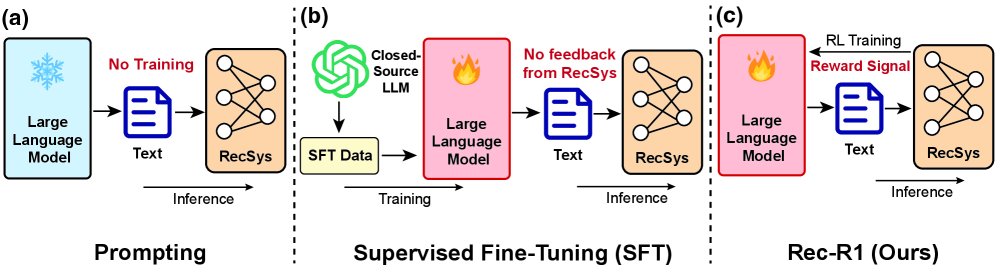
Comparison of Prompting, SFT, and Rec-R1 paradigms. It highlights the closed loop in Rec-R1.
Evaluation Highlights
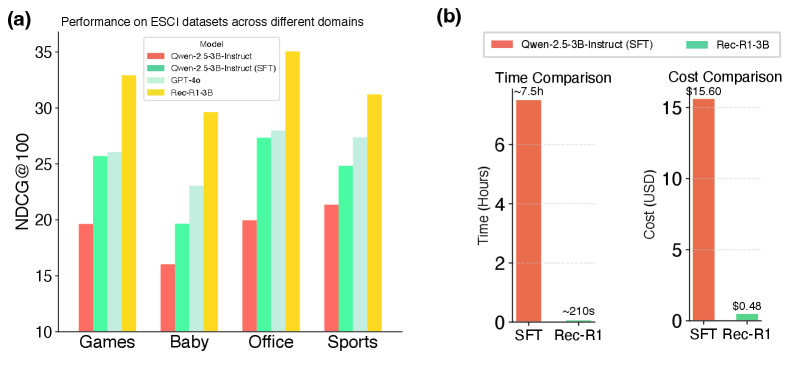
- +21.45 NDCG@100 improvement on ESCI (Video Games) using Rec-R1 with a BM25 retriever compared to the base BM25 baseline
- +18.76 NDCG@100 improvement on ESCI (Video Games) using Rec-R1 with a BLAIR dense retriever compared to the base BLAIR baseline
- Preserves instruction-following capabilities (maintaining IFEval scores) while SFT causes a ~27-point drop, demonstrating prevention of catastrophic forgetting
Breakthrough Assessment
8/10
Strong conceptual advance by replacing SFT proxy objectives with direct RL optimization on black-box feedback. The empirical gains are very large (>20%), and it addresses the fundamental 'alignment' problem in LLM4Rec.