📝 Paper Summary
Generative Recommendation
Item Tokenization / Indexing
Multi-modal Recommendation
SimCIT replaces reconstruction-based item tokenization with a contrastive learning framework that aligns multi-modal signals (text, image, spatial graphs) into discrete identifiers for more discriminative generative recommendation.
Core Problem
Existing generative recommenders use reconstruction-based quantization (e.g., RQ-VAE) to create item tokens, which prioritizes reconstructing embeddings over distinguishing between items and fails to effectively integrate multi-modal signals.
Why it matters:
- Reconstruction objectives conflict with the retrieval goal of discrimination, leading to ambiguous tokens for semantically similar items (representation collapse)
- Current methods struggle to incorporate crucial side information like spatial constraints in POI (Point-of-Interest) tasks, reducing accuracy in industrial deployments
- Inefficient tokenization creates redundancy in the token space, hampering the scalability required for large-scale industrial systems
Concrete Example:
In a POI recommendation task, a reconstruction-based tokenizer might assign similar tokens to two restaurants based solely on similar textual descriptions, ignoring that they are in different cities. SimCIT integrates spatial graph views via contrastive learning, forcing the tokens to reflect geographical proximity and mobility patterns.
Key Novelty
Simple Contrastive Item Tokenization (SimCIT)
- Replaces the standard reconstruction loss (MSE) in quantization with a contrastive objective, treating different item modalities (image, text, graph) as 'views' to be aligned
- Uses a learnable residual quantization module that acts as a bridge between modalities, ensuring the discrete identifier captures shared semantics without needing to reconstruct exact input vectors
- Introduces a hierarchical identifier learning paradigm that systematically integrates heterogeneous data, specifically handling spatial graphs for location-based services
Architecture
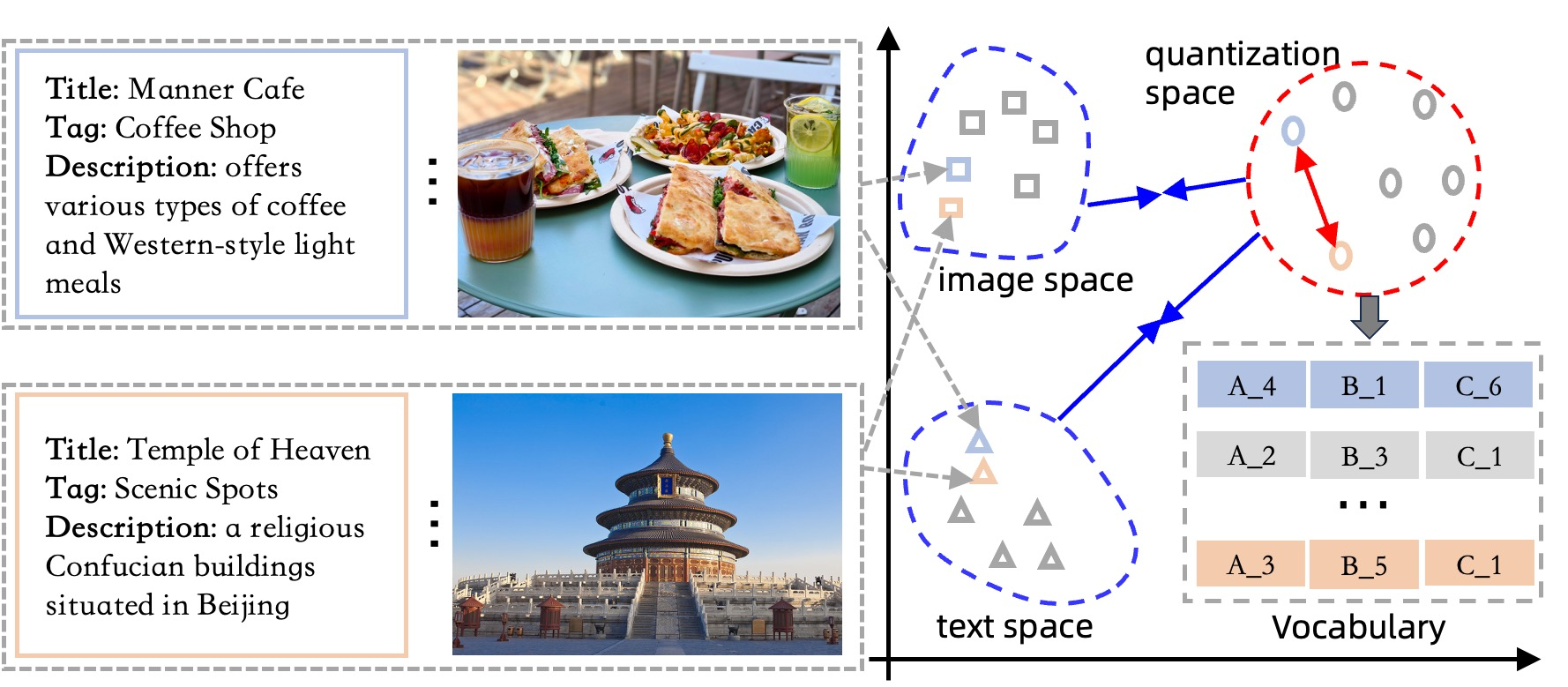
Conceptual comparison between TIGER (reconstruction-based) and SimCIT (contrastive-based) tokenization. Shows the mapping of items to discrete tokens via multi-modal alignment.
Breakthrough Assessment
7/10
Proposes a logical shift from reconstruction to contrastive learning for tokenization, addressing a clear bottleneck in generative recommendation. While the idea is sound and aligns with trends in representation learning, the paper is an arXiv preprint with results not visible in the provided snippet.