📝 Paper Summary
Continual Pre-training (CPT)
Knowledge Injection
Knowledge-Instruct transforms small raw text corpora into information-dense synthetic instruction-response pairs to inject new knowledge into LLMs without catastrophic forgetting or breaking chat templates.
Core Problem
Standard Continual Pre-training (CPT) on small corpora (~100K tokens) fails because LLMs require vast repetition to internalize facts, and unsupervised training on raw text degrades instruction-following capabilities.
Why it matters:
- LLMs struggle with niche, domain-specific, or new information not present in their massive pre-training datasets.
- Existing CPT methods work well for large datasets (billions of tokens) but suffer from catastrophic forgetting and poor learning efficiency in low-data regimes.
- Standard unsupervised CPT breaks the chat template of instruction-tuned models, requiring an additional expensive fine-tuning phase to restore conversational ability.
Concrete Example:
A manual or textbook might cover a topic in only ~100K tokens. When standard CPT is applied to this small amount of data, the model fails to learn the facts due to lack of repetition and variations. For instance, in the 'Companies' dataset of 23 fictional companies, standard CPT resulted in near-zero accuracy on factual questions about those companies.
Key Novelty
Knowledge-Instruct
- Synthesizes a massive amount of diverse instruction-response pairs from a small document corpus, focusing on entities and facts rather than just raw text prediction.
- Uses a multi-step pipeline (extract entities, extract facts, contextualize, deduplicate, paraphrase) to create high-quality synthetic training data that forces the model to learn facts through supervised fine-tuning (SFT).
- Injects knowledge directly into instruction-tuned models, avoiding the need for a separate unsupervised pre-training stage that degrades chat capabilities.
Architecture
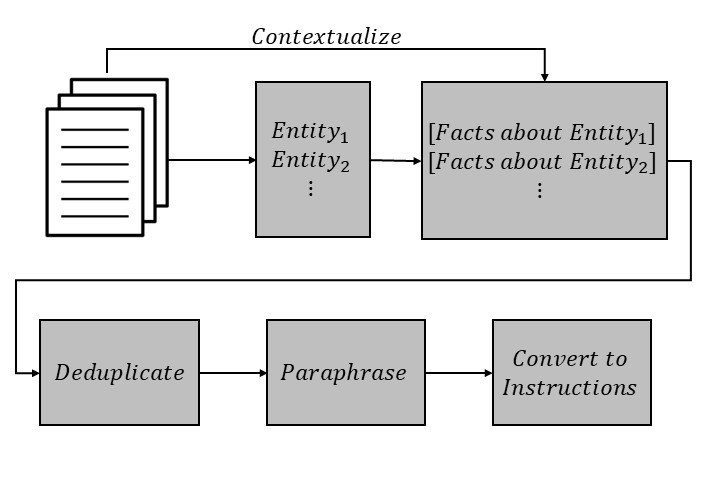
The six-step data generation pipeline for Knowledge-Instruct.
Evaluation Highlights
- Achieves >80% accuracy on the Companies dataset (entirely new knowledge) with Llama-3.1-8B, while standard CPT and Rephrase CPT remain near 0%.
- Outperforms standard CPT and Synthetic CPT on PopQA (long-tail knowledge), surpassing even GPT-4o on specific long-tail queries.
- Improves multi-hop reasoning on MultiHop-RAG by +24.4 points (Acc) using Llama-3.1-8B compared to standard CPT in oracle settings.
Breakthrough Assessment
8/10
Strong practical contribution for domain adaptation in low-data regimes. Solves the 'chat template breakage' issue of CPT while significantly outperforming standard methods on memorization.