📝 Paper Summary
Agent Recommendation
Agentic Information Retrieval
AgentSelect standardizes heterogeneous evaluations into a unified benchmark for recommending deployable agent configurations (model + tools) based on natural language queries.
Core Problem
The ecosystem lacks a principled way to choose among an exploding space of LLMs and tools; existing benchmarks evaluate components in isolation rather than as deployable configurations.
Why it matters:
- Practitioners face a 'jungle of configurations' when building agents, needing to select backbone models and toolsets without guidance
- Current evaluation artifacts (leaderboards) are fragmented and diagnostic, failing to provide the query-conditioned supervision needed to train recommenders
- Popularity-based recommendation methods fail in the agent domain due to the shift from dense reuse to long-tail, near one-off supervision
Concrete Example:
A user wants an agent to 'analyze stock trends and plot a graph'. While separate benchmarks rank LLMs on math and tools on API usage, no single source tells the user which specific combination (e.g., GPT-4 + Matplotlib + YahooFinance) is best for that specific narrative query.
Key Novelty
Unified Narrative Query-to-Agent Recommendation Benchmark
- Formalizes agent recommendation as ranking capability profiles (M, T) composed of a backbone Model and Toolset
- Converts heterogeneous evaluation artifacts (LLM leaderboards, tool benchmarks) into a standardized positive-only interaction dataset
- Synthesizes compositional agents for realistic tasks by retrieving and coupling compatible models and tools, creating pseudo-positive supervision where real data is scarce
Architecture
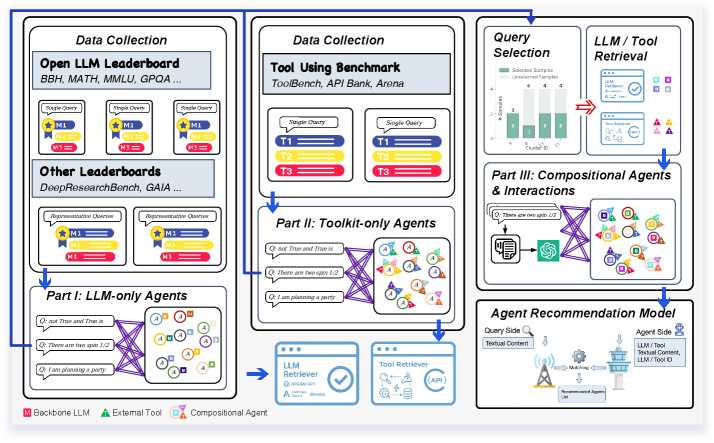
Overview of the AgentSelect framework, illustrating the pipeline from benchmark construction to recommender training and deployment.
Evaluation Highlights
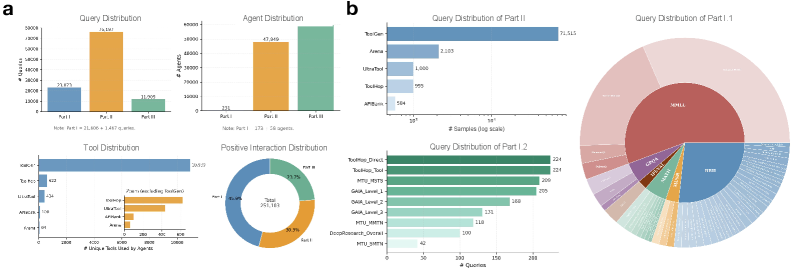
- Constructed a large-scale benchmark with 111,179 queries and 107,721 deployable agents from 40+ sources
- Unified 251,103 positive-only query-agent interaction records across LLM-only, toolkit-only, and compositional settings
- Aggregated tool usage covering 12,099 unique tools, significantly expanding beyond single-source tool benchmarks like ToolHop (622 tools)
Breakthrough Assessment
9/10
Establishes the first unified infrastructure for the 'last mile' of agent deployment—selection. By converting fragmented leaderboards into training data, it enables a new class of meta-agent systems.