📝 Paper Summary
Sequential Recommendation
In-Context Learning (ICL)
LLMSRec-Syn improves sequential recommendation by synthesizing multiple user histories into a single, compact 'aggregated demonstration' prompt, overcoming context length limits and information sparsity.
Core Problem
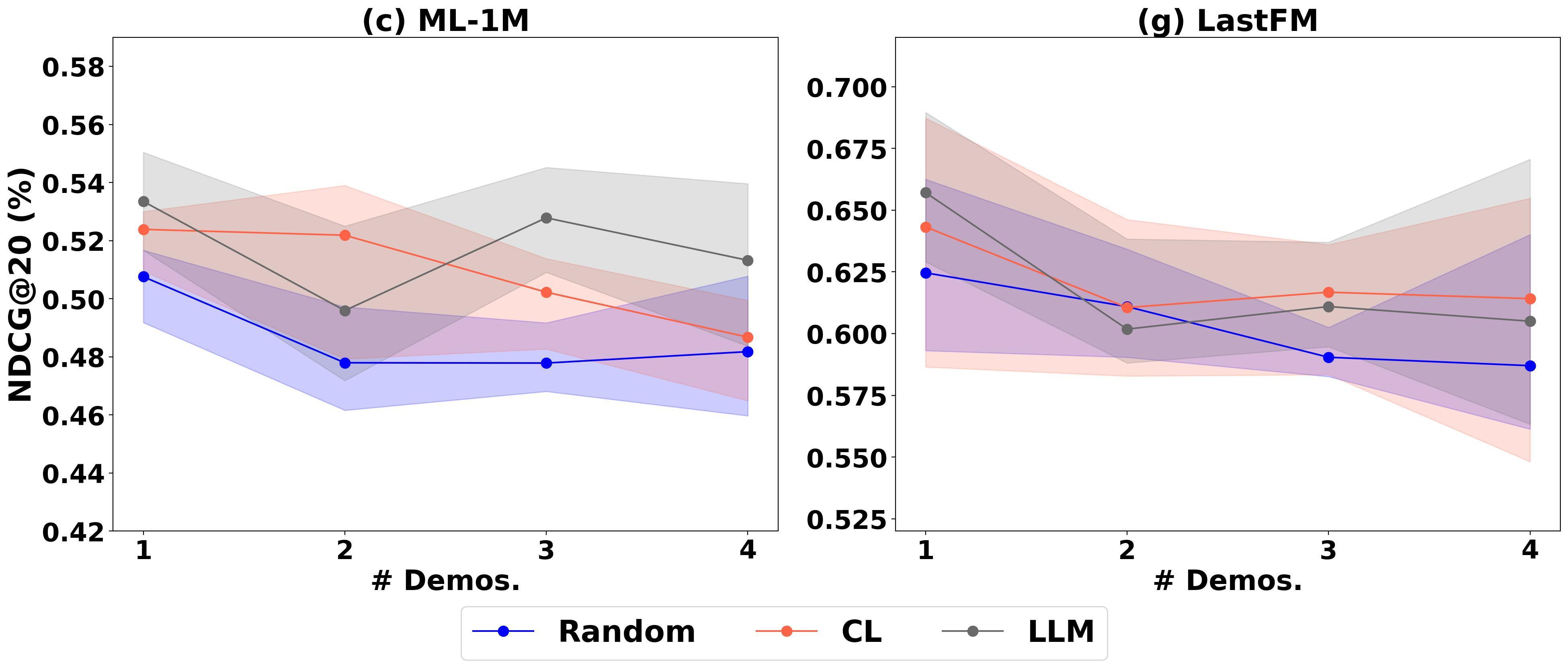
Standard few-shot in-context learning for sequential recommendation fails to scale: adding more individual user demonstrations degrades performance due to context length limits and information overload.
Why it matters:
- LLMs struggle to process long, repetitive prompts containing multiple distinct user histories, often losing focus on relevant details (known as the 'lost in the middle' phenomenon)
- Single-user demonstrations are often too sparse to capture the complex patterns needed for accurate recommendation
- Existing ICL methods for recommendation perform poorly compared to traditional supervised learning models (like SASRec)
Concrete Example:
If a test user likes Sci-Fi, a standard few-shot prompt might stack 3 full histories of other Sci-Fi users. This becomes too long for the LLM, which gets confused or truncates the input. LLMSRec-Syn instead creates one fake 'super-user' history combining the key Sci-Fi interactions from all 3 users.
Key Novelty
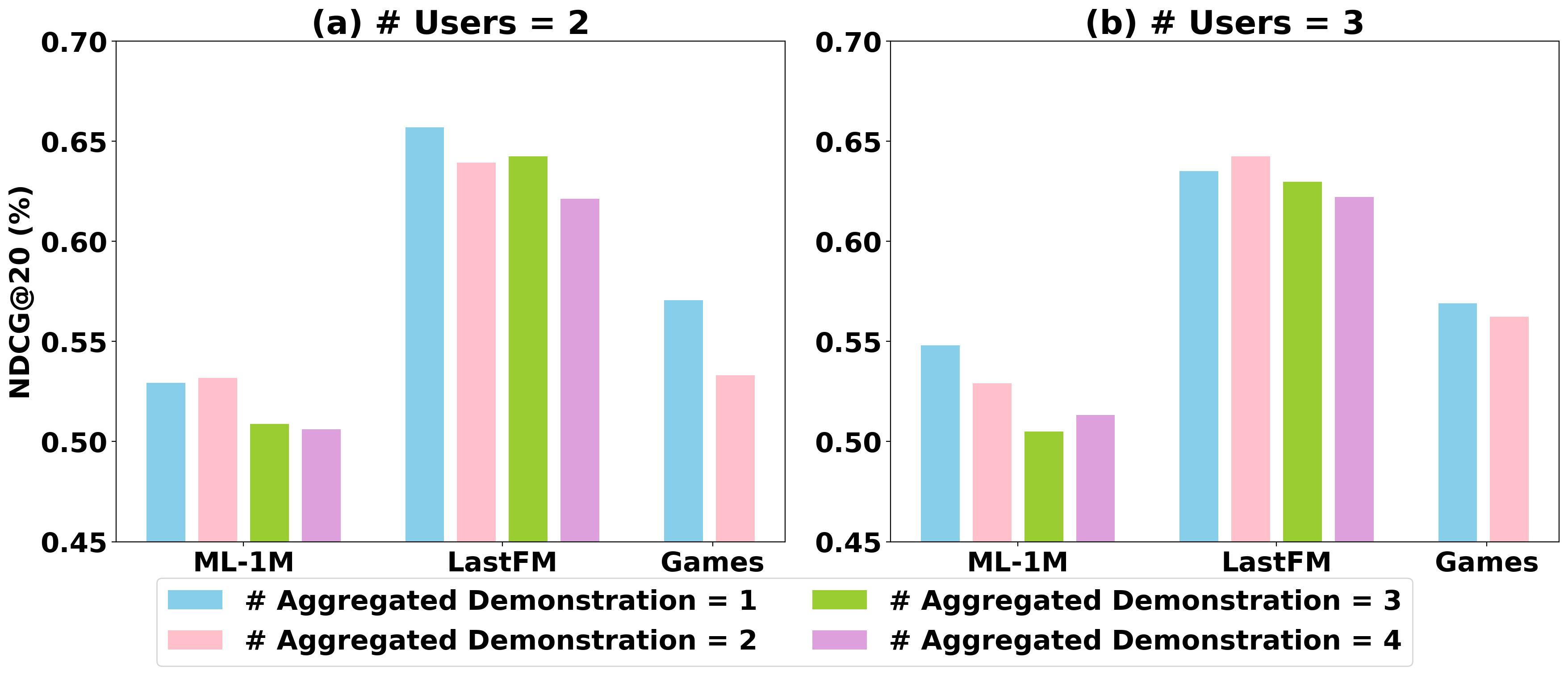
Aggregated Demonstrations (LLMSRec-Syn)
- Instead of stacking multiple distinct user demonstrations (User A history + User B history), the method merges items from multiple relevant users into a single, synthetic user history sorted chronologically.
- This approach reduces token usage by removing repeated instruction boilerplate and presents the LLM with a denser, more informative signal about item transitions.
Architecture
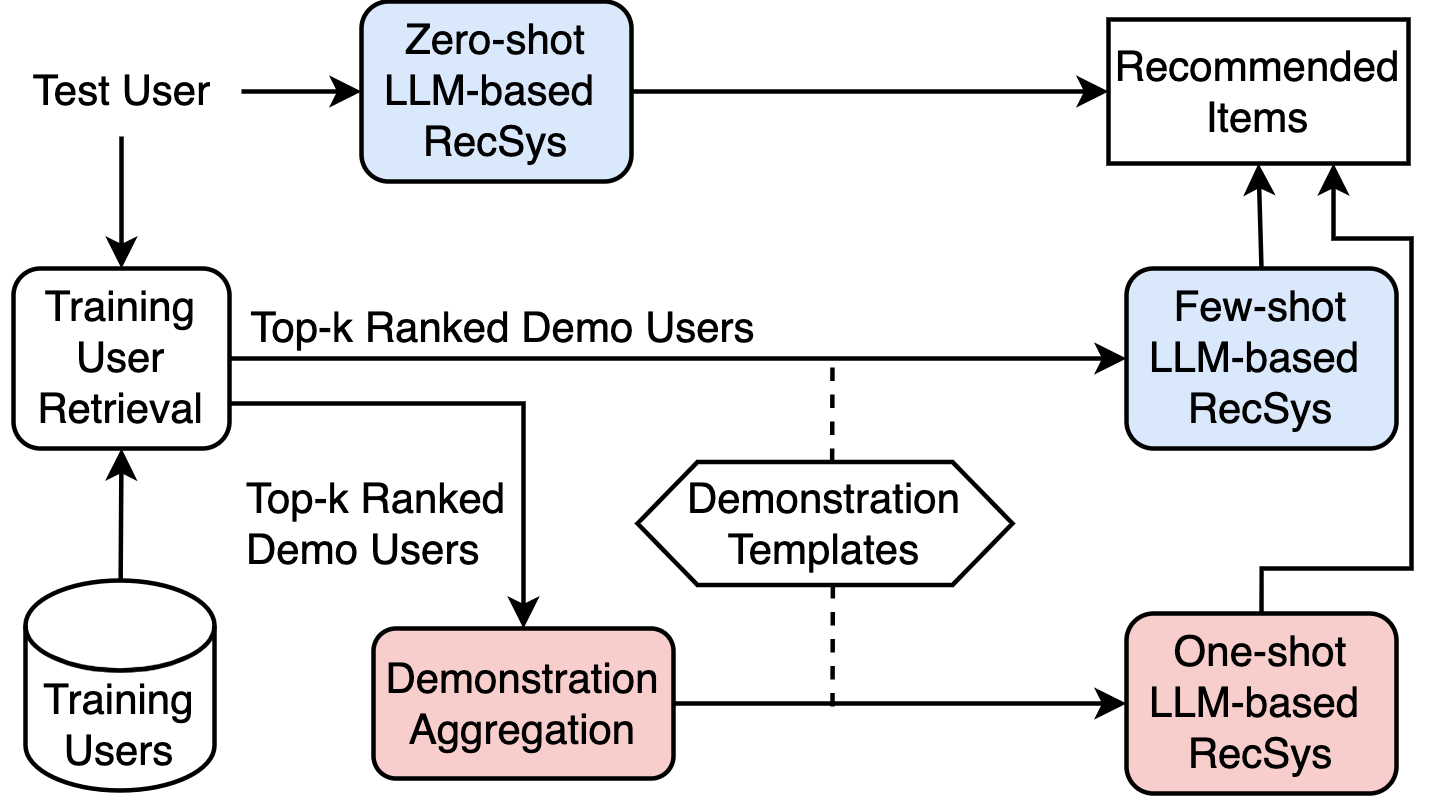
Comparison of Zero-shot, Few-shot, and the proposed Aggregated One-shot frameworks.
Evaluation Highlights
- LLMSRec-Syn outperforms standard 1-shot ICL by +16.7% (NDCG@10) on the MovieLens-1M dataset.
- Surpasses state-of-the-art zero-shot methods (like Hou et al. 2023) by significant margins across three datasets (ML-1M, Games, LastFM).
- Achieves parity with or exceeds supervised baselines (like SASRec) in specific low-data or sparse settings (e.g., on LastFM).
Breakthrough Assessment
7/10
Offers a clever, simple prompting strategy that effectively solves the context-window bottleneck for few-shot recommendation, turning a failure case (more shots = worse performance) into a success.