📝 Paper Summary
Conversational Recommender Systems (CRS)
LLM Fine-tuning
USB-Rec enhances LLM-based conversational recommendation by generating synthetic preference data for reinforcement learning and employing an inference-time self-enhancement strategy where the model simulates a user to score its own potential responses.
Core Problem
Existing LLM-based CRSs rely on complex prompting pipelines without enhancing the model's intrinsic capabilities, while standard fine-tuning (SFT) leads to overfitting and Reinforcement Learning (RL) typically requires expensive human feedback.
Why it matters:
- Traditional SFT (Supervised Fine-Tuning) models often overfit to training items, failing to generalize to the dynamic nature of multi-turn conversations
- Reliance on prompting alone limits the model's ability to fundamentally understand recommendation strategies
- Collecting human preference data for RL in conversational settings is labor-intensive and difficult to scale
Concrete Example:
In a standard pipeline, if a user rejects a movie recommendation, an SFT-trained model might rigidly repeat similar items or fail to pivot because it mimics noisy training data. USB-Rec's RL-trained model, having learned from a simulator's negative feedback during training, can adapt its strategy to explore different genres.
Key Novelty
User-Simulator-Based Framework (USB-Rec)
- Training: Uses a 'Preference Optimization Dataset Construction Strategy' (PODCS) where a simulated user interacts with the recommender; high-scoring dialogues become positive samples and original labels become negative samples for RL.
- Inference: Uses a 'Self-Enhancement Strategy' (SES) where the model creates an internal user simulator to play out future conversation turns for multiple candidate responses, selecting the one that yields the best simulated outcome.
Architecture
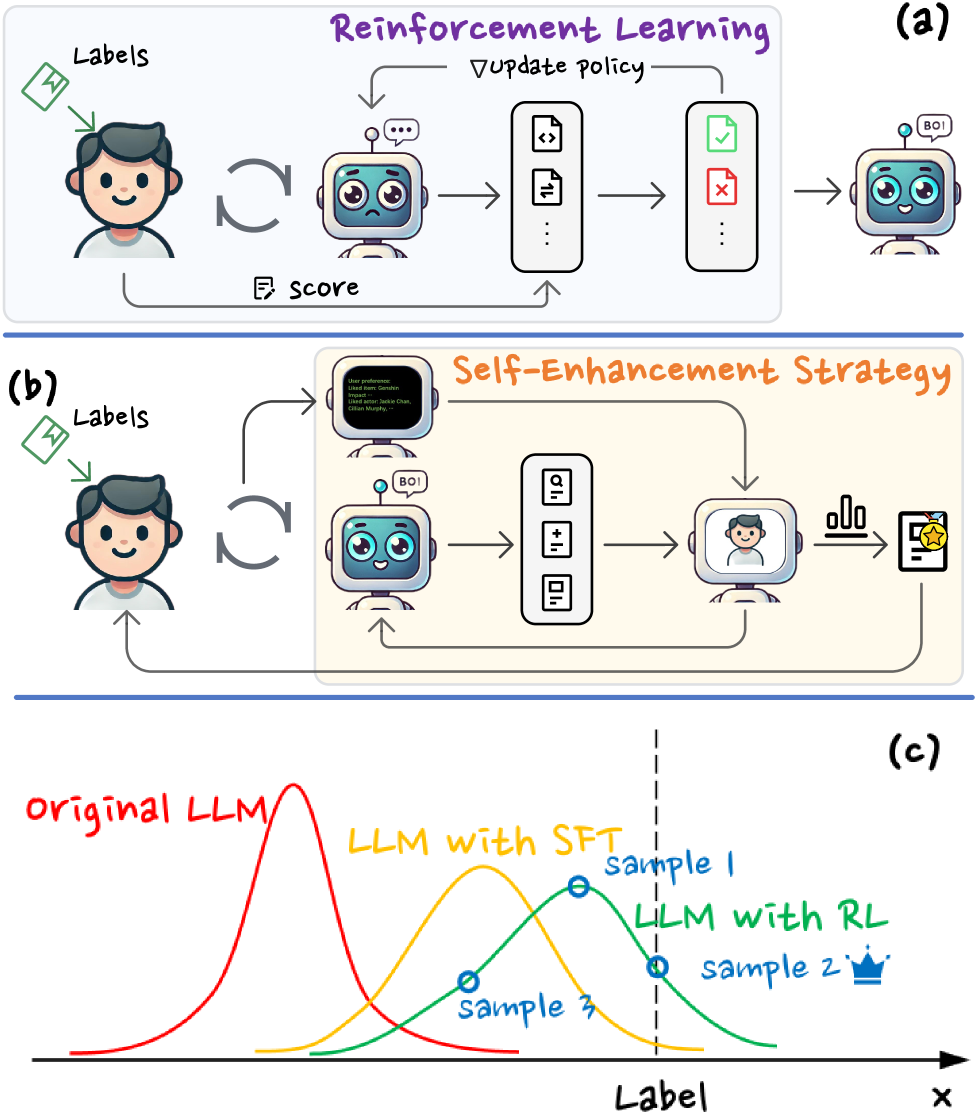
The overall framework consisting of (a) Preference Optimization Dataset Construction (PODCS) for training and (b) Self-Enhancement Strategy (SES) for inference.
Evaluation Highlights
- Achieves highest iEval scores on ReDial (1.29) and OpenDialKG (1.40) benchmarks, outperforming GPT-4 and ReFICR.
- Maintains competitive Recall@1 performance (0.300 on OpenDialKG), surpassing GPT-4 (0.246) and ReFICR (0.283).
- Demonstrates consistent gains across multiple LLM backbones (Llama-3, ChatGLM3, Qwen2.5) when applying the framework.
Breakthrough Assessment
7/10
A strong application of RLAIF (Reinforcement Learning from AI Feedback) to the specific domain of conversational recommendation. The combination of training-time simulation and inference-time search is well-motivated and effective, though the core components (user simulators, preference optimization) are established techniques adapted here.