📝 Paper Summary
Next Point-of-Interest (POI) Recommendation
Generative Retrieval
Spatio-Temporal Modeling
GeoGR adapts Large Language Models for next-POI prediction by encoding locations into hierarchical semantic IDs that explicitly capture spatio-temporal collaborative patterns, then training the model via continued pre-training and supervised fine-tuning.
Core Problem
Existing LLM-based POI recommenders rely on non-semantic identifiers or purely textual embeddings that fail to capture collaborative cross-category relationships (e.g., airport→hotel→parking) and struggle with the sparsity of real-world navigation data.
Why it matters:
- Accurate prediction is critical for large-scale navigation platforms serving billions of users with diverse needs (dining, tourism, fueling).
- Traditional sequential models miss the semantic reasoning of LLMs, while standard LLM approaches miss the structured spatio-temporal dependencies inherent in mobility data.
Concrete Example:
A user searches for 'dinner' near a specific location. A standard LLM might recommend a generic popular restaurant based on text similarity. GeoGR, understanding the user's specific trajectory (e.g., arriving from an airport), recommends a hotel restaurant with parking, leveraging learned collaborative signals between these distinct categories.
Key Novelty
Geo-Aware Generative Recommendation Framework
- Constructs 'Semantic IDs' (SIDs) for POIs not just from text, but by explicitly modeling geographically constrained co-visitation patterns using contrastive learning.
- Aligns the LLM with these new SIDs through a two-stage process: Continued Pre-Training (CPT) on template-based tasks to learn the 'language' of SIDs, followed by Supervised Fine-Tuning (SFT) for the specific next-POI prediction task.
Architecture
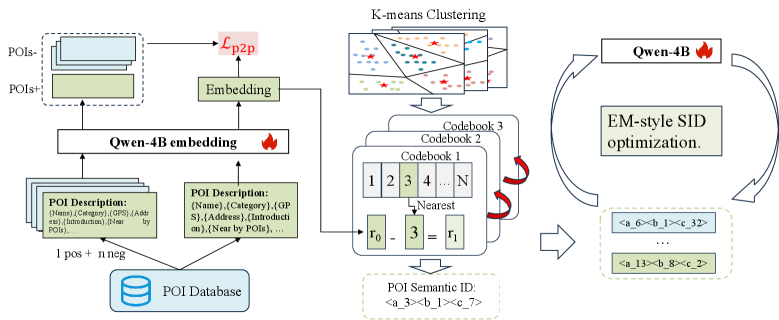
The overall framework of GeoGR, split into two main stages: (1) Geo-aware SID Construction and (2) Generative POI Recommendation Training.
Evaluation Highlights
- Online A/B testing on the AMAP platform (millions of users) demonstrated significant boosting of multiple online metrics.
- Offline experiments on real-world datasets show superiority over state-of-the-art baselines (specific numbers not provided in snippet but claimed).
Breakthrough Assessment
8/10
Strong industrial application with a novel approach to 'grounding' LLMs in spatio-temporal data via specialized tokenization. Successfully deployed on a massive scale (AMAP).