📝 Paper Summary
Recommendation Systems
Sequential Recommendation
Loss Function Analysis
The paper demonstrates that the perceived superiority of LLM-based recommenders stems from unfair loss function comparisons and proposes Scaled Cross-Entropy (SCE) to enable conventional models to achieve comparable or superior performance efficiently.
Core Problem
LLM-based recommenders are often compared to conventional models (like SASRec) that are trained with inferior losses (BCE/BPR) rather than the Cross-Entropy loss used by LLMs, creating an illusion of LLM superiority.
Why it matters:
- Researchers are possibly over-estimating LLM capabilities and under-estimating conventional methods due to unfair benchmarking
- Full Cross-Entropy is computationally intractable for large item sets in production, necessitating efficient but accurate approximations
- Existing approximations like Noise Contrastive Estimation (NCE) suffer from slow convergence and weak bounds in early training
Concrete Example:
In current benchmarks, SASRec trained with BCE/BPR underperforms against LlamaRec. However, the paper shows SASRec trained with full Cross-Entropy actually outperforms LlamaRec, proving the gap is due to the loss function, not the model architecture.
Key Novelty
Scaled Cross-Entropy (SCE) for Recommendation
- Theoretically proves that minimizing Cross-Entropy (CE) maximizes a lower bound of ranking metrics (NDCG and RR), explaining why CE is superior to BCE/BPR for ranking
- Identifies that standard Noise Contrastive Estimation (NCE) provides a weak bound during early training, leading to slow convergence
- Proposes SCE: a sampled softmax loss where the negative term is scaled up by a weight factor to maintain a tight bound on the ranking metric even with few samples
Architecture
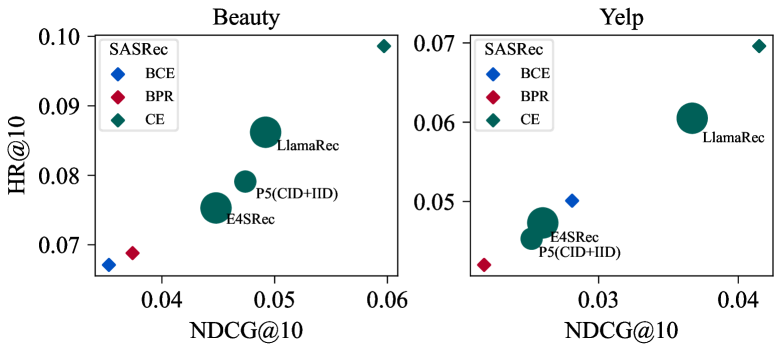
Comparison of ranking performance between SASRec trained with different losses (CE, BCE, BPR) and LLM-based methods
Evaluation Highlights
- SASRec trained with Cross-Entropy outperforms LLM-based methods by a large margin (Figure 1 qualitative result)
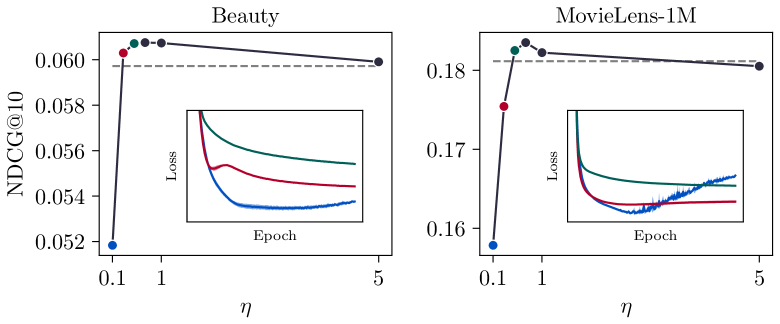
- Scaled Cross-Entropy (SCE) with only 100 negative samples and scaling factor 100 achieves comparable performance to standard sampled softmax with 500 samples on the Beauty dataset
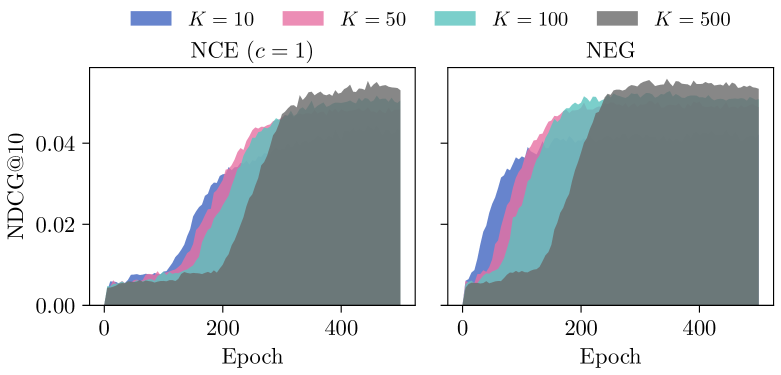
- Standard NCE requires ~150 epochs to converge on Beauty, while NEG (Negative Sampling) converges in ~70 epochs, highlighting NCE's training difficulties
Breakthrough Assessment
7/10
Provides a critical correction to the evaluation methodology of LLMs in RecSys. While the architectural contribution is a loss modification, the impact on fair benchmarking is significant.