📝 Paper Summary
Recommender Systems
Large Language Model Integration
Representation Learning
LEARN improves recommendations by using frozen LLMs as item encoders and a specialized transformer to align open-world semantic knowledge with collaborative user preferences, avoiding the high cost of text-based fine-tuning.
Core Problem
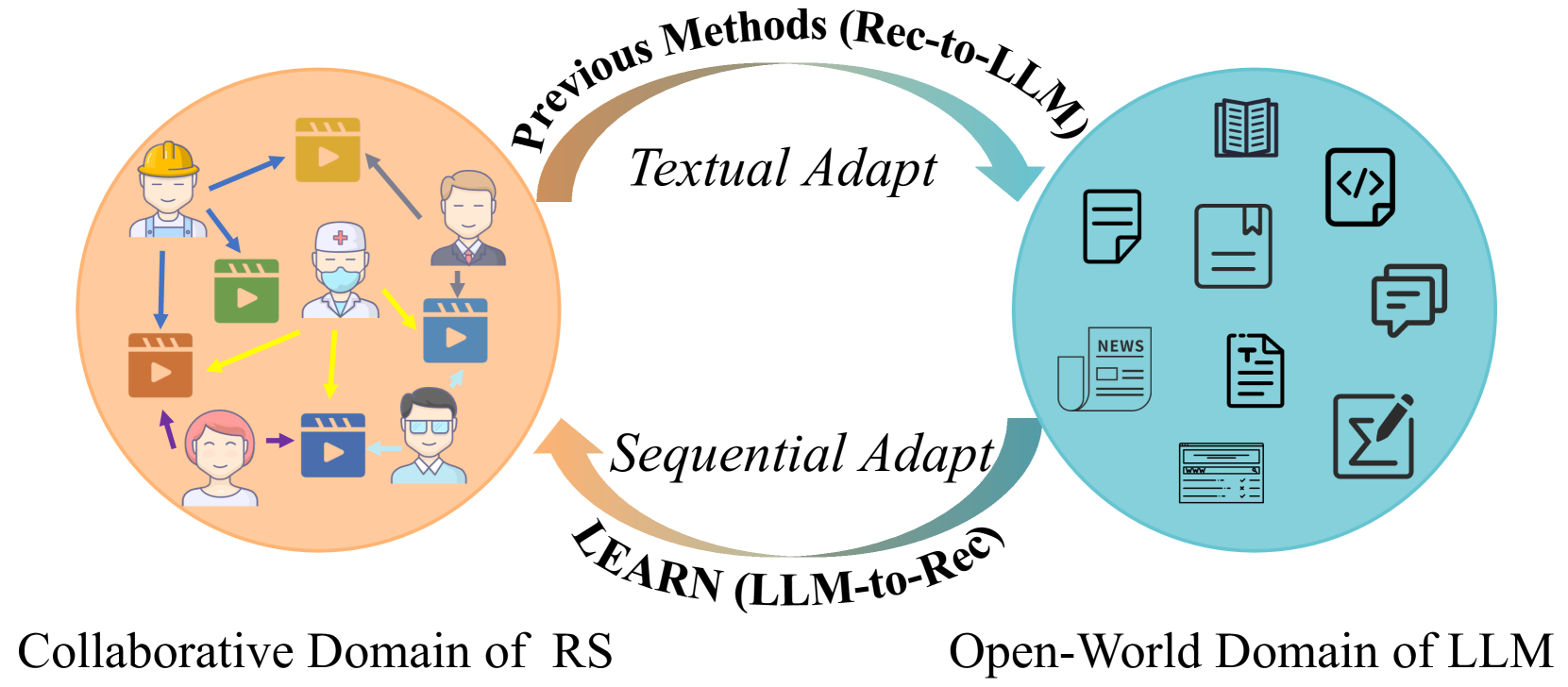
Traditional recommender systems rely on ID embeddings that lack semantic understanding, while integrating LLMs via 'Rec-to-LLM' (converting history to text) is computationally prohibitive and causes catastrophic forgetting.
Why it matters:
- Industrial constraints (e.g., 800+ item histories) make standard LLM fine-tuning or inference unaffordable ($O(N^2)$ complexity on long contexts)
- ID-based methods fail in cold-start scenarios and cannot transfer knowledge across domains like pre-trained models in CV or NLP
- Fine-tuning LLMs on collaborative data often degrades their general open-world reasoning capabilities (catastrophic forgetting)
Concrete Example:
In a short video platform where a user watches ~800 videos weekly, converting this multi-month history into a text prompt for an LLM exceeds context windows and compute budgets. Existing 'Rec-to-LLM' methods fail to handle this scale efficiently.
Key Novelty
LLM-driven KnowlEdge Adaptive RecommeNdation (LEARN)
- Inverts the paradigm from 'Rec-to-LLM' to 'LLM-to-Rec': instead of forcing rec data into LLM formats, it extracts semantic vectors from a frozen LLM and adapts them to recommendation tasks
- Separates content extraction (via frozen LLM) from preference alignment (via a trainable transformer), preserving open-world knowledge while learning collaborative patterns
- Uses a twin-tower architecture where the item encoder shares weights with the user tower, optimized via contrastive learning on dense user actions
Architecture
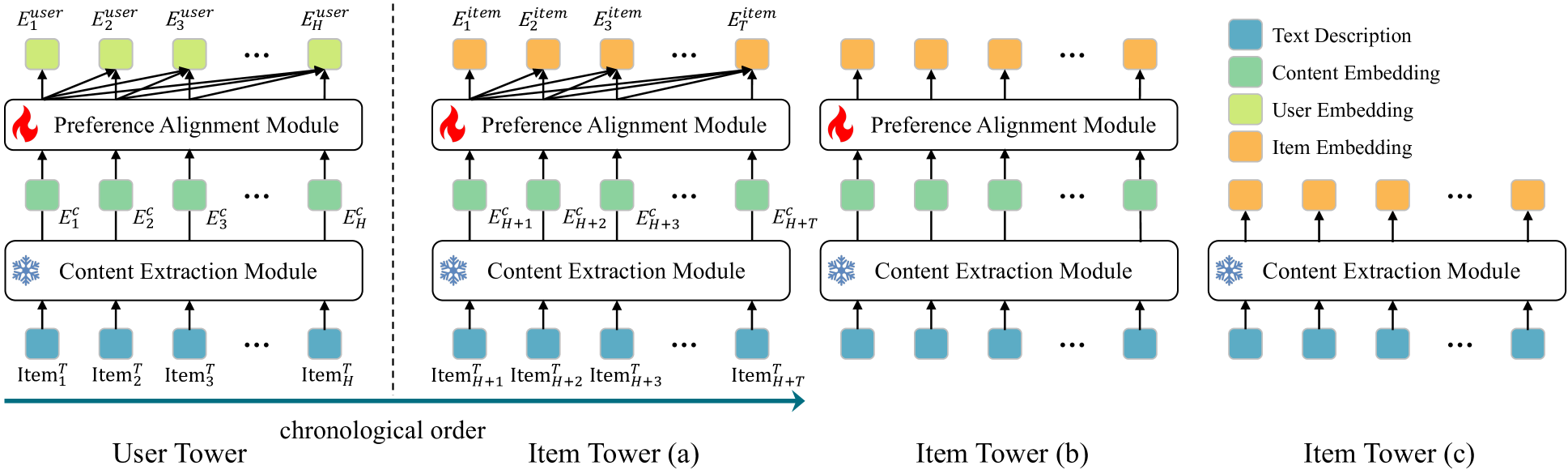
The overall LEARN framework consisting of a User Tower and Item Tower.
Evaluation Highlights
- Achieves an average 13.95% improvement in Recall@10 across six Amazon Review datasets compared to state-of-the-art baselines
- Successfully deployed in a real large-scale industrial short video platform (verified via online A/B testing)
- State-of-the-art performance in three metrics across six public datasets (Amazon Reviews)
Breakthrough Assessment
8/10
Significant for proposing a scalable 'LLM-to-Rec' architecture that works in industrial settings (proven by A/B tests) and achieving double-digit gains on public benchmarks, effectively addressing the efficiency-effectiveness trade-off in LLM4Rec.