📝 Paper Summary
Conversational Recommender Systems (CRSs)
LLM-based Agents
LLMCRS functions as a central manager that decomposes conversational recommendation into sub-tasks, dispatches them to expert models, and optimizes the workflow using reinforcement learning based on performance feedback.
Core Problem
Conversational Recommender Systems (CRSs) involve multiple sub-tasks (elicitation, recommendation, explanation) that require precise management, yet current approaches struggle to effectively coordinate these tasks or generate high-quality responses.
Why it matters:
- Existing CRSs often fail to decide *when* to recommend versus *when* to ask for preferences, leading to disjointed user experiences.
- End-to-end generation models often lack the specific proficiency of expert recommendation algorithms.
- Preliminary LLM approaches only rerank outputs or rewrite responses, missing the opportunity to manage the full conversation logic.
Concrete Example:
A user might ask 'Why recommend this?', requiring an explanation sub-task. A standard system might mistakenly treat this as a request for new items or fail to retrieve the specific item attributes needed for a logic-based explanation.
Key Novelty
LLM-based Manager with Reinforcement Learning from Performance Feedback (RLPF)
- Decouples the system into a 'Manager' (LLM) and 'Executors' (Expert Models). The LLM detects sub-tasks using schema-based prompts and selects the right expert model via dynamic matching.
- Uses Reinforcement Learning (RLPF) to fine-tune the LLM, treating the entire generation pipeline as an action and using recommendation accuracy and dialogue quality as reward signals.
Architecture
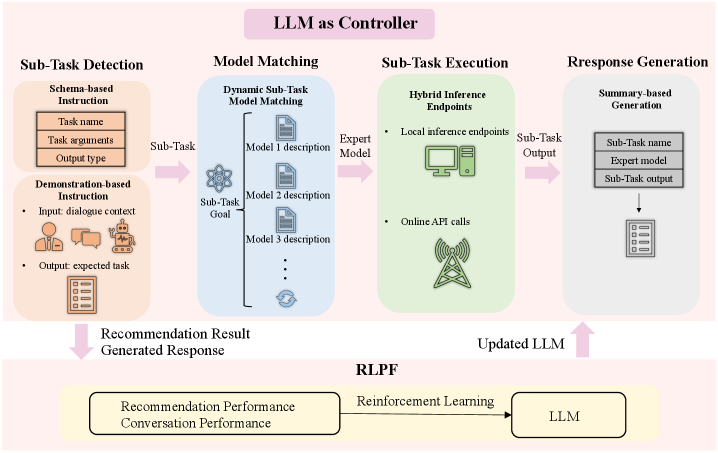
The workflow of LLMCRS, illustrating the four-stage process managed by the LLM.
Evaluation Highlights
- Achieves 0.2903 Distinct-2 score on TG-ReDial with LLaMA, a ~3x improvement over the TG-ReDial baseline (0.0960), indicating significantly more diverse responses.
- Outperforms the TG-ReDial baseline on BLEU-1 by +3.75% (0.0601 vs 0.0226) using LLaMA, showing better overlap with human reference responses.
- Demonstrates effective sub-task management by dynamically selecting expert models from a candidate set using text-based descriptions.
Breakthrough Assessment
7/10
Strong conceptual framework for decomposing CRSs using LLMs. The application of RL to fine-tune the manager based on downstream metric feedback is a significant methodological step, though the results rely partly on diversity metrics.