📝 Paper Summary
Recommender Systems
Generative LLMs
GIRL is a generative job recommendation system that creates personalized job descriptions from resumes, refined by recruiter feedback via reinforcement learning.
Core Problem
Traditional job recommendation systems rely on opaque 'black-box' matching scores and are limited to ranking existing database entries, failing to provide explainable guidance or synthesized career advice.
Why it matters:
- Job seeking is a high-stakes scenario where user trust and explainability are critical, but black-box neural networks lack transparency.
- Discriminative models can only retrieve existing jobs, limiting their ability to act as comprehensive AI advisors that suggest ideal career paths or synthesized roles.
- A significant semantic gap often exists between the language in CVs and Job Descriptions (JDs), hindering effective matching.
Concrete Example:
A traditional model might output a 0.8 matching score for a candidate and a job without explanation. In contrast, GIRL generates a full Job Description specifically tailored to the candidate's CV, showing exactly what an ideal role looks like for them.
Key Novelty
Generative Paradigm for Job Recommendation (GIRL)
- Instead of ranking existing jobs, the model generates a hypothetical 'perfect' Job Description (JD) based on a candidate's CV.
- Uses a three-stage training pipeline (SFT, Reward Modeling, RL) to align the LLM's generation not just with language patterns, but with actual recruiter preferences (market demand).
- The generated description serves two purposes: providing interpretable career advice to the user and acting as a data augmentation feature to improve traditional matching models.
Architecture
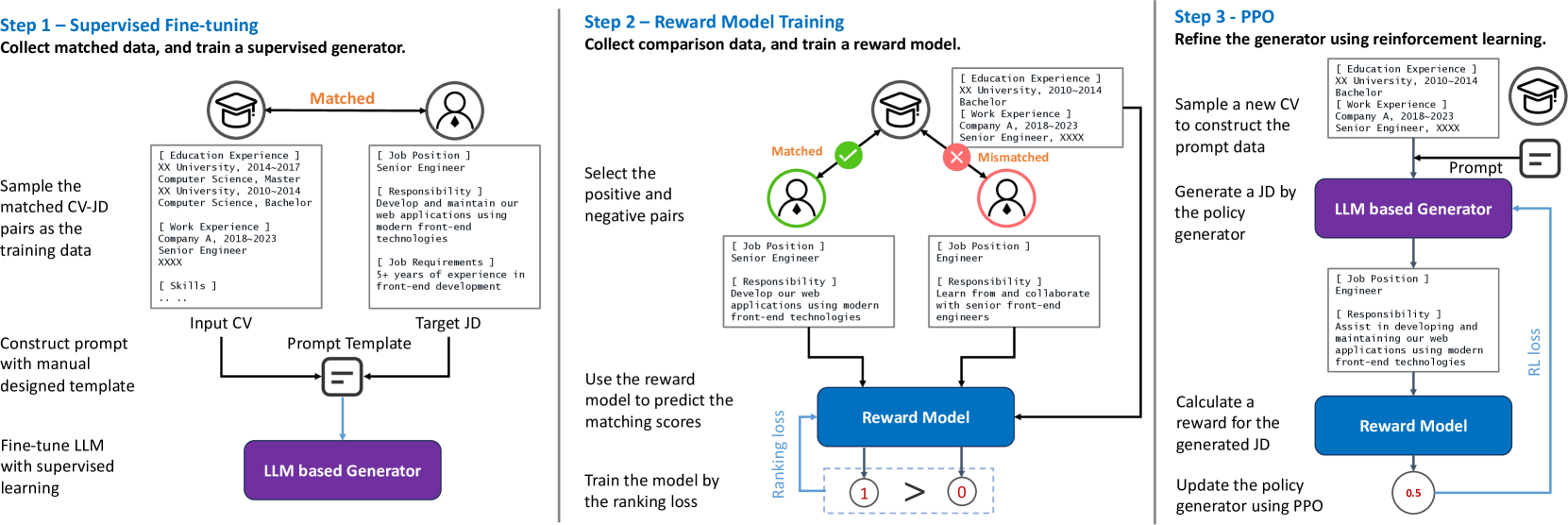
The overall framework of GIRL, illustrating the three-step training process: Supervised Fine-Tuning (SFT), Reward Model Training, and Reinforcement Learning (RL).
Evaluation Highlights
- Outperforms state-of-the-art baselines on generation metrics, achieving higher BLEU and ROUGE scores compared to vanilla LLMs.
- Improves traditional matching tasks: using generated JDs as auxiliary features boosts the AUC of a BERT-based matching model.
- RL training aligns model output with recruiter preferences, yielding higher reward scores compared to SFT-only models.
Breakthrough Assessment
7/10
Novel application of Generative AI to job recommendation (generation vs. retrieval). The proposed pipeline effectively adapts RLHF to the recruitment domain, though the evaluation relies heavily on internal datasets.
