📝 Paper Summary
LLM-based Recommender Systems
Recommender AI Agents
Model Explainability
RecAI is a comprehensive toolkit that integrates Large Language Models into recommender systems through agents, domain-specific fine-tuning, knowledge prompting, and explainability modules to enhance versatility and user interaction.
Core Problem
LLMs lack specific knowledge of item catalogs and dynamic user preferences, while traditional recommender systems lack the language understanding and interactivity required for conversational user experiences.
Why it matters:
- Traditional RSs act as static retrieval systems, failing to support complex, natural language user intents
- Directly applying general LLMs to recommendation fails because they cannot access real-time inventory or specific domain attributes not present in their pre-training data
- Existing solutions often require high latency (10-20 seconds) for multi-step reasoning, degrading the user experience
Concrete Example:
A user might ask for 'games like Elden Ring but cheaper.' A traditional RS only processes clicks/IDs. A general LLM might know the game but not the current prices. RecAI's agent connects the natural language request to a SQL tool to check prices and an embedding tool to match game style.
Key Novelty
Five Pillars of LLM-RS Integration
- Recommender AI Agent (InteRecAgent): Treats the LLM as a 'brain' that plans and calls traditional RS models as 'tools' (e.g., for retrieval or ranking)
- RecLM (Recommendation-oriented LM): Fine-tunes LMs specifically to understand collaborative patterns (RecLM-gen) or align text with item embeddings (RecLM-emb)
- Knowledge Plugin (DOKE): Injects domain knowledge into prompts dynamically without fine-tuning, acting as a lightweight adapter for closed-source LLMs
Architecture
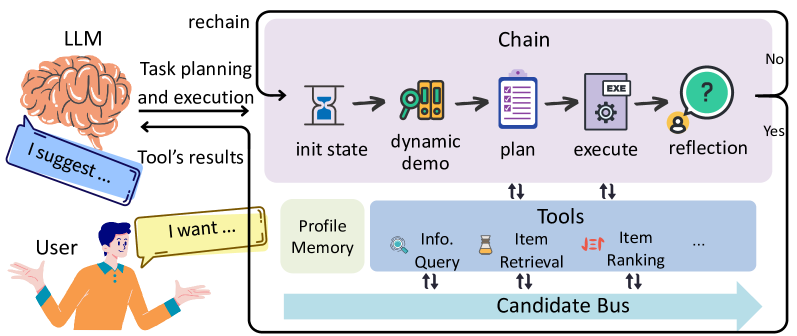
The architecture of the InteRecAgent (Recommender AI Agent).
Evaluation Highlights
- RecLM-gen reduces system latency by eliminating the 10-20 second delays typical of multi-step agent frameworks via streaming token generation
- Fine-tuned Llama-2-chat (7B) surpasses GPT-4 in item ranking tasks
- RecLlama (fine-tuned Llama-7B) outperforms GPT-3.5-turbo in instruction-following for recommender agent tasks
Breakthrough Assessment
8/10
A significant consolidation of multiple state-of-the-art approaches (agents, fine-tuning, explainability) into a single open-source toolkit. While a survey of the authors' own works, the toolkit approach lowers the barrier for adoption.