📝 Paper Summary
Video Large Language Models (Video-LLMs)
Efficient Multimodal Learning
SlowFast-LLaVA-1.5 is a family of efficient video-LLMs that processes videos using two streams—one for detailed spatial semantics at low frame rates and one for motion cues at high frame rates—to achieve state-of-the-art long-form video understanding.
Core Problem
Existing Video LLMs struggle to balance the need for high frame counts (to understand long videos) with computational efficiency, often requiring complex multi-stage training pipelines and massive internal datasets.
Why it matters:
- Processing long-form videos requires handling thousands of tokens, which is computationally prohibitive for standard LLMs on consumer hardware
- Current methods often sacrifice fine-grained spatial details to fit long temporal contexts, or vice versa
- Complex training recipes with internal data hinder reproducibility and adoption by the open-source community
Concrete Example:
When answering a question about a specific short action within an hour-long movie, standard models either drop frames (missing the action) or downsample resolution too aggressively (missing the visual details), whereas SlowFast-LLaVA-1.5 captures both via separate pathways.
Key Novelty
SlowFast Two-Stream Projector for Video LLMs
- Incorporates a SlowFast mechanism into the visual projector: a 'Slow' pathway captures high-resolution spatial details at a low frame rate, while a 'Fast' pathway captures motion context at a high frame rate with low resolution
- Uses a streamlined two-stage training pipeline (Image SFT → Joint Video-Image SFT) using only publicly available datasets, avoiding complex pre-training stages
Architecture
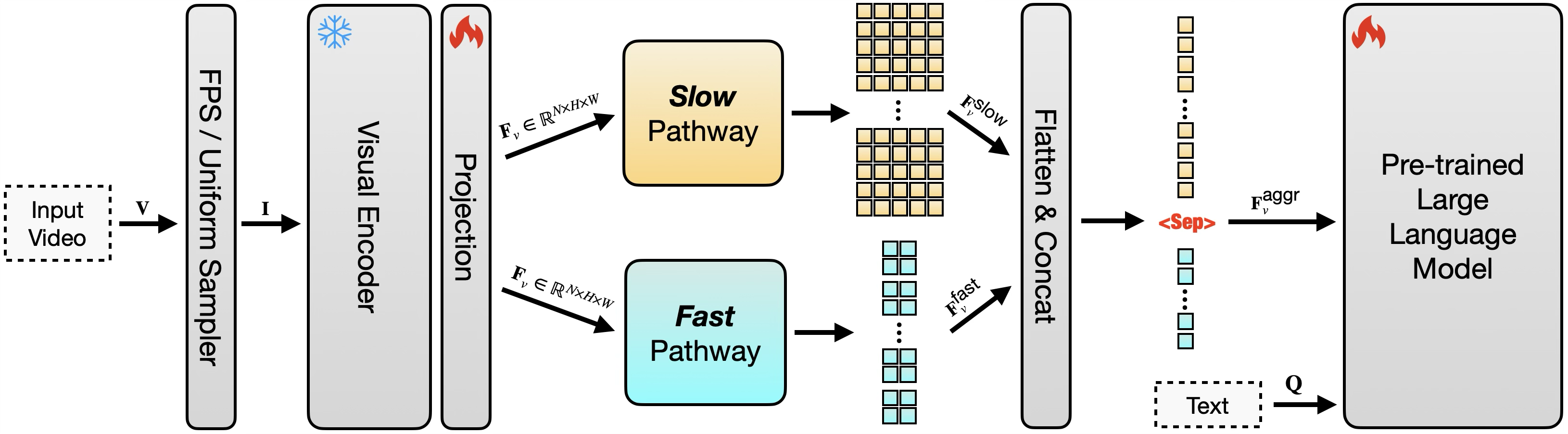
The overall architecture of SlowFast-LLaVA-1.5, illustrating the two-stream projector and the training pipeline.
Evaluation Highlights
- Achieves 71.5% on MLVU and 62.5% on LongVideoBench with the 7B model, outperforming existing methods in long-form video understanding
- The 1B and 3B models achieve 56.6% and 60.8% respectively on Video-MME (w/o subtitles), outperforming comparable small-scale Video LLMs
- Maintains strong image understanding capabilities alongside video performance due to joint training
Breakthrough Assessment
8/10
Significantly advances efficient video understanding, achieving SOTA on long-context benchmarks with smaller models (1B/3B) and a reproducible, public-data-only training recipe.