📝 Paper Summary
Sequential Recommendation
Large Language Models (LLMs) for Recommendation
AdaptRec improves sequential recommendation by enabling an LLM to actively evaluate and select relevant similar user histories to serve as in-context demonstrations, rather than relying solely on static embedding similarities.
Core Problem
Existing methods integrate collaborative signals into LLMs using static, numerical similarity metrics (e.g., Euclidean distance) that do not align with the LLM's reasoning process, often retrieving uninformative demonstrations.
Why it matters:
- Standard collaborative filtering metrics fail to capture the semantic nuances necessary for LLM reasoning, leading to prompts that confuse rather than guide the model
- Searching the vast space of user interactions for demonstrations is computationally expensive without an efficient filtering mechanism
- Static selection methods cannot adapt to the specific context of the current prediction task, resulting in suboptimal in-context learning performance
Concrete Example:
A traditional system might select a 'similar' user based on shared item IDs (numerical overlap), but if the *sequence* or *context* of purchase differs (e.g., gift-buying vs. personal use), the demonstration will mislead the LLM. AdaptRec allows the LLM to read the sequence and reject it if the behavioral pattern doesn't match.
Key Novelty
Self-Adaptive Prompting Framework
- Uses a two-phase selection strategy: a coarse-grained embedding retrieval followed by a fine-grained, LLM-driven selection where the model explicitly evaluates candidate user similarities
- Treats user histories as natural language demonstrations, transforming collaborative signals (patterns of other users) into an explicit format the LLM can process via in-context learning
Architecture
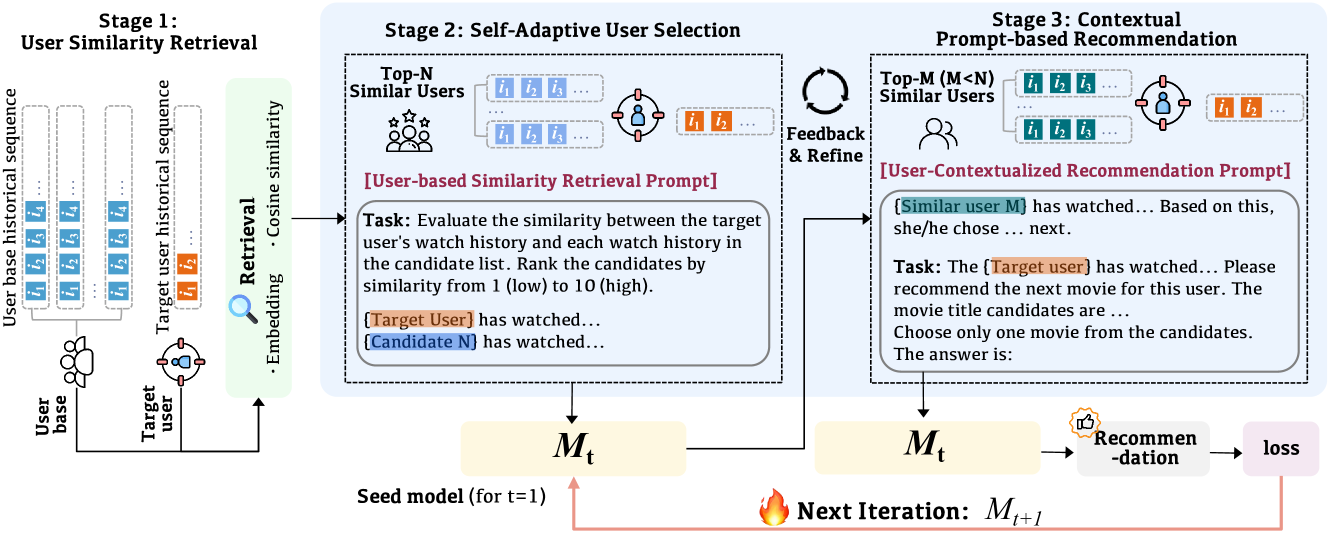
The overall AdaptRec framework comprising three stages: User Similarity Retrieval, Self-Adaptive User Selection, and Contextual Prompt-based Recommendation.
Evaluation Highlights
- Achieves HitRatio@1 improvements of 7.13%, 18.16%, and 10.41% across three real-world datasets using full fine-tuning compared to state-of-the-art baselines
- Outperforms baselines significantly in few-shot scenarios, with HitRatio@1 gains of 23.00%, 15.97%, and 17.98%
- Demonstrates effective integration of collaborative signals where the LLM actively selects inputs rather than passively consuming pre-filtered data
Breakthrough Assessment
7/10
Novel integration of LLM-based evaluation into the retrieval loop for recommender systems. Strong reported improvements, though the reliance on standard LLM backbones limits architectural novelty.