📝 Paper Summary
LLM-based Recommendation
Instruction Tuning
ITDR is a large-scale instruction tuning dataset comprising nearly 200,000 instances across seven subtasks, designed to bridge the gap between user behavior data and LLM natural language understanding.
Core Problem
LLMs struggle with recommendation tasks because traditional data (IDs) lacks natural language structure, and existing instruction datasets are too small or lack diverse task descriptions.
Why it matters:
- Structural discrepancy between ID-based behavior records and natural language limits LLM effectiveness in modeling user preferences
- Existing datasets lack structured task descriptions essential for guiding LLMs, hindering generalization to varied recommendation scenarios
- Current methods face a 'data bottleneck' where training data fails to cover multifaceted task scenarios and user behavior patterns
Concrete Example:
Traditional datasets provide only ID sequences (e.g., User 123 clicked Item 456), which contain no semantic information for an LLM to reason about, unlike ITDR's natural language instructions that explicitly describe the task and context.
Key Novelty
Standardized Instruction Tuning Dataset for Recommendation (ITDR)
- Unifies recommendation data into two root tasks: User-Item Interaction (predicting preferences) and User-Item Understanding (profiling items/users)
- Transforms 13 classic benchmarks into standardized natural language templates with specific task descriptions to guide LLM reasoning
Architecture
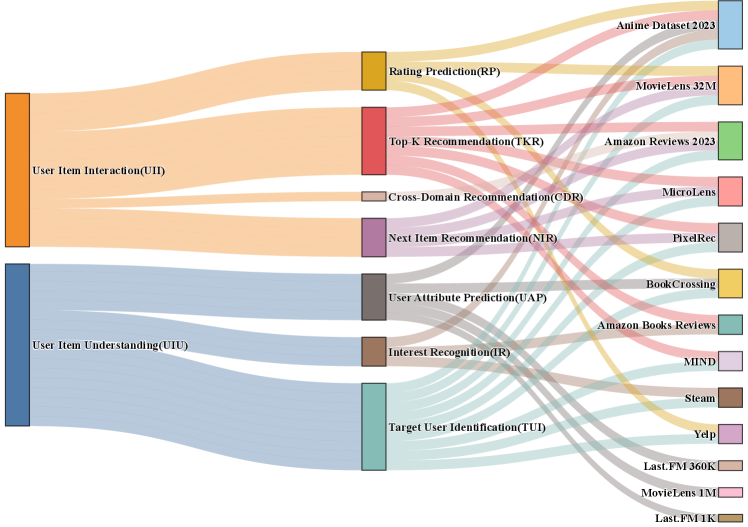
Taxonomy of the ITDR dataset showing the division into Root Tasks and Subtasks
Evaluation Highlights
- Constructed a dataset of 195,065 high-quality instructions across 7 distinct subtasks
- Integrates data from 13 diverse public recommendation benchmarks (e.g., MovieLens 32M, Amazon Reviews, PixelRec)
- Validates effectiveness on mainstream models including GLM-4, Qwen2.5, and LLaMA-3.2 (qualitative result from abstract, specific numbers not in provided text)
Breakthrough Assessment
7/10
Addresses a critical data bottleneck in LLM-RecSys with a large-scale, structured resource. While the method is standard instruction tuning, the dataset scale and taxonomy are significant contributions.