📝 Paper Summary
Language-based User Profiles
LLM-based Recommendation
LangPTune optimizes LLMs to generate language-based user profiles by treating the downstream recommender's performance as a reward signal, enabling end-to-end training that outperforms zero-shot approaches.
Core Problem
Existing language-based recommendation methods rely on zero-shot or few-shot LLM inference to generate user profiles, which are not optimized for the specific recommendation objective and often yield suboptimal performance.
Why it matters:
- Language-based profiles offer transparency and scrutability that opaque embedding vectors lack, allowing users to understand and steer recommendations
- Current methods fail to align the natural language profile generation with the actual ranking capability of the downstream system
- There is a trade-off between the interpretability of text profiles and the accuracy of dense embeddings; bridging this gap is crucial for adoption
Concrete Example:
A zero-shot LLM might summarize a user's history as 'likes sci-fi movies', which is human-readable but too generic for a recommender to distinguish between 'Star Wars' and 'Interstellar'. LangPTune trains the LLM to generate a profile like 'prefers space operas with high action', which the recommender can use to rank items more effectively.
Key Novelty
Reinforcement Learning for System Optimization (RLSO)
- Treats the recommendation system (decoder) as an environment that provides feedback (ranking quality) to the LLM (encoder)
- Iteratively updates the LLM to generate profiles that maximize downstream ranking performance using a reinforcement learning approach similar to RLHF but with system feedback instead of human preferences
Architecture

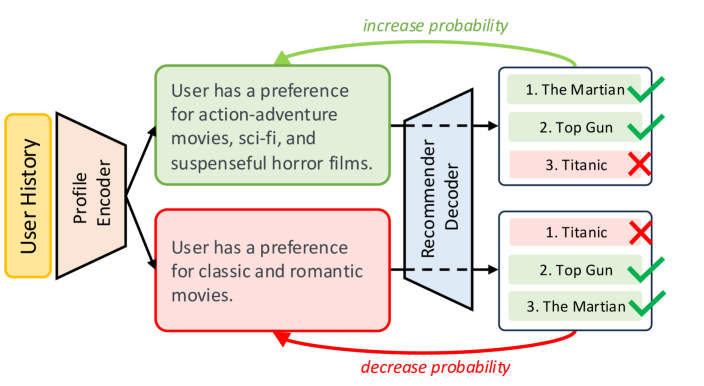
The inference pipeline of LangPTune. A profile encoder (LLM) takes item history to generate a text profile, which a recommender decoder uses to rank items.
Evaluation Highlights
- LangPTune with Llama-3-8B-it outperforms the best zero-shot baseline by +17.5% on the pixel dataset (Recall@10)
- Matches or exceeds the performance of state-of-the-art embedding-based methods (SASRec) on 2 out of 3 datasets while maintaining interpretability
- User studies confirm that profiles optimized via RLSO maintain human readability and interpretability comparable to zero-shot profiles
Breakthrough Assessment
8/10
First end-to-end training pipeline for language-based user profiles that successfully bridges the gap between interpretability and recommendation performance.