📊 Experiments & Results
Evaluation Setup
Cross-domain rating prediction and ranking on Amazon Reviews subsets
Benchmarks:
- Amazon Reviews (Books -> Movies) (CDR Rating/Ranking)
- Amazon Reviews (Movies -> Music) (CDR Rating/Ranking)
- Amazon Reviews (Electronics -> Food) (CDR Rating/Ranking)
Metrics:
- RMSE (Root Mean Squared Error)
- MAE (Mean Absolute Error)
- MRR@10 (Mean Reciprocal Rank)
- NDCG@10 (Normalized Discounted Cumulative Gain)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Ranking task results showing LLM performance vs baselines across domain pairs. | ||||
| Amazon Reviews Pair 1 | MRR@10 | 0.2596 | 0.308 | +0.0484 |
| Amazon Reviews Pair 1 | NDCG@10 | 0.3646 | 0.383 | +0.0184 |
| Amazon Reviews Pair 2 | MRR@10 | 0.2611 | 0.346 | +0.0849 |
| Amazon Reviews Pair 2 | NDCG@10 | 0.3822 | 0.412 | +0.0298 |
| Rating task results demonstrating LLM proficiency in rating prediction, sometimes even without target data. | ||||
| Amazon Reviews Pair 1 | RMSE | 1.0655 | 0.783 | -0.2825 |
| Amazon Reviews Pair 2 | RMSE | 0.9859 | 0.641 | -0.3449 |
Experiment Figures
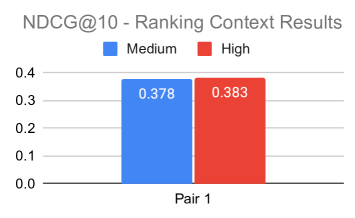
Bar charts comparing performance of 'Medium Context' vs 'High Context' prompts across domain pairs.
Main Takeaways
- LLMs outperform state-of-the-art CDR baselines in ranking and rating tasks for intuitively similar domain pairs (e.g., Books->Movies).
- For rating prediction, LLMs often perform better using *only* source domain data ('no target injection') than when target data is included, suggesting target data might introduce noise for the LLM's reasoning process.
- High-context prompts (detailed task descriptions) consistently outperform medium-context prompts.
- LLMs struggle to generalize in completely unrelated domain pairs (Electronics->Food), performing worse than baselines in ranking tasks.