📝 Paper Summary
Explainable Recommendation
LLM for Recommendation
LLMXRec is a two-stage framework that decouples recommendation from explanation, using instruction-tuned Large Language Models to generate high-quality, controllable text explanations for items suggested by any base recommender.
Core Problem
Existing explainable recommendation methods often sacrifice accuracy for explainability (embedded methods) or rely on rigid templates that lack fluency and reasoning capabilities (post-hoc methods).
Why it matters:
- Black-box recommender systems lack transparency, reducing user trust and adoption
- Previous methods using small language models struggle with fluency and complex reasoning compared to modern LLMs
- Coupled approaches (training recommendation and explanation jointly) constrain the choice of recommendation models
Concrete Example:
A traditional post-hoc method might output a rigid template like 'People also bought X', which is generic. LLMXRec takes a user's history and the item 'Wireless Mouse' to generate: 'Given your interest in computer accessories like keyboards, this wireless mouse is recommended for its high precision and ergonomic design.'
Key Novelty
LLMXRec (Large Language Model for Explainable Recommendations)
- Decouples the system into two stages: Stage 1 generates recommendations using any standard model; Stage 2 uses an LLM to generate explanations for those specific items
- Treats explanation generation as a conditional text generation task, fine-tuning the LLM with specific instructions that incorporate user history, item features, and Chain-of-Thought reasoning
- Introduces a novel evaluation protocol using LLMs as discriminators (judges) to rank explanation quality, alongside human evaluation
Architecture
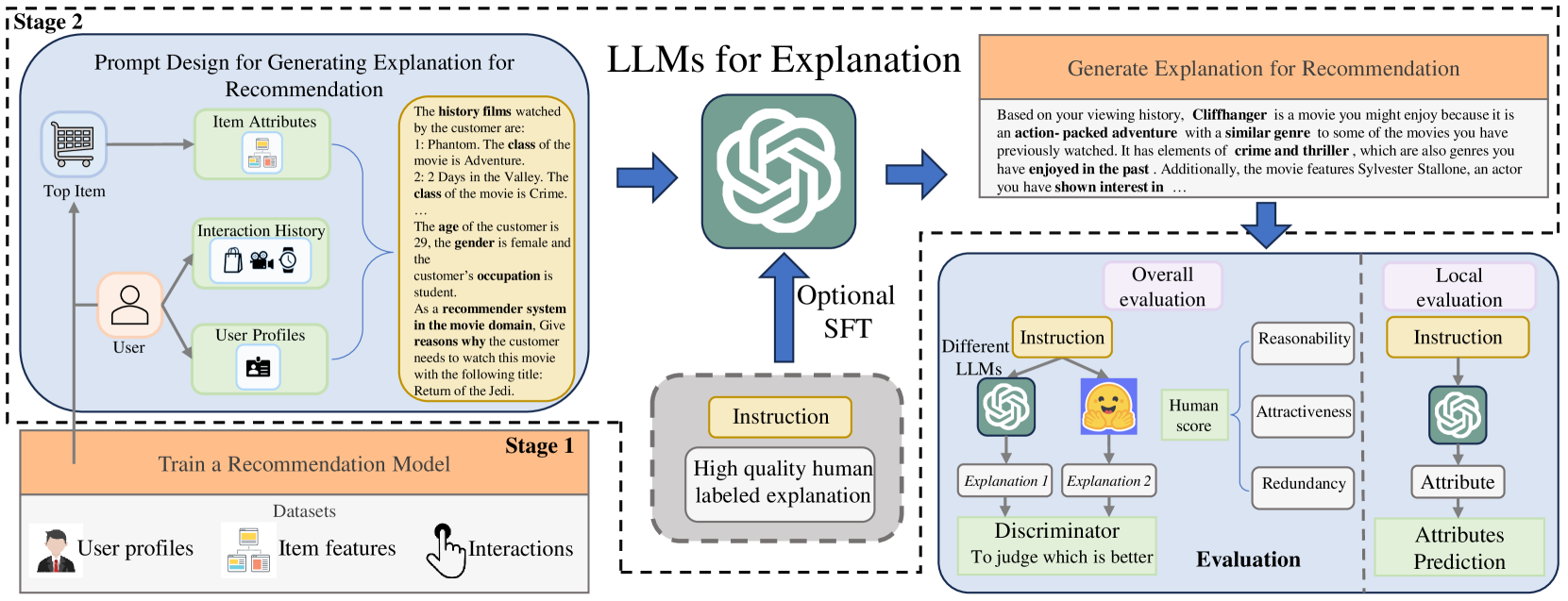
The overall architecture of the LLMXRec framework, illustrating the decoupling of the recommendation model and the explanation generator.
Evaluation Highlights
- Instruction-tuned LLaMA-7B achieves 80.0% win-rate against baseline PEPLER on the Yelp dataset according to GPT-4 evaluation
- Human evaluation rates LLMXRec explanations higher in 'Reasonableness' (2.42 vs 2.13) compared to the PEPLER baseline on the TripAdvisor dataset
- Attribute prediction accuracy (a proxy for local explanation quality) reaches 85.5% on Yelp, demonstrating the model accurately captures item features
Breakthrough Assessment
7/10
A solid application of LLMs to the post-hoc explanation problem. The decoupling allows flexibility, and the use of LLMs as discriminators for evaluation is a practical contribution, though the fundamental architecture is a standard instruction-tuning pipeline.