📝 Paper Summary
LLM-based Recommendation
Zero-Shot Learning
LLMs can perform effective zero-shot next-item recommendation by using a multi-step prompting strategy that infers user preferences and ranks items within a pre-filtered candidate set.
Core Problem
Directly using LLMs for recommendation fails because the item space is too large for the context window, and LLMs lack specific knowledge of a user's interaction history.
Why it matters:
- Traditional recommender systems require extensive training data and cannot function in zero-shot scenarios (new domains/tasks)
- Standard LLM prompting yields poor accuracy (e.g., HR@10 of 0.0297) due to hallucinations and inability to rank huge catalogs
- Bridging general-purpose LLM reasoning with specific recommendation tasks is crucial for cold-start scenarios
Concrete Example:
If a user has watched 'Toy Story' and 'Shrek', a simple prompt asking 'Recommend 10 movies' might return random popular movies or hallucinations not in the database. The proposed NIR (Next-Item Recommendation) approach first filters to 20 relevant candidates, asks the LLM to summarize that the user likes 'animated comedies', and then ranks the candidates based on that summary.
Key Novelty
Zero-Shot Next-Item Recommendation (NIR) Prompting
- Uses an external heuristic (User/Item Filtering) to narrow the millions of items down to a small 'Candidate Set' that fits in the prompt
- Decomposes the recommendation task into three explicit LLM reasoning steps: (1) Summarize user taste, (2) Pick representative history, (3) Rank candidates
- Enforces a strict output format (e.g., 'watched movie <- candidate movie') to map LLM text generation back to specific database item IDs
Architecture
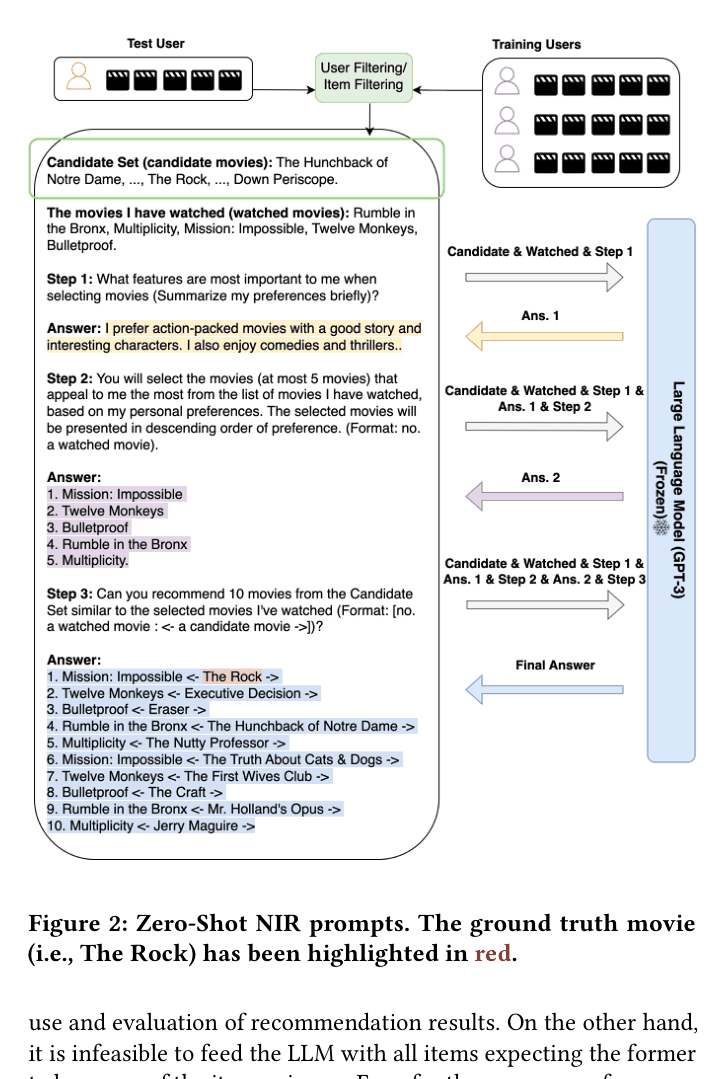
The 3-Step Zero-Shot NIR Prompting Strategy workflow.
Evaluation Highlights
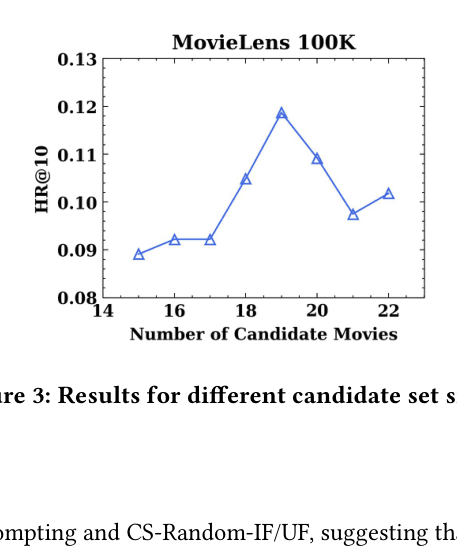
- Outperforms fully trained FPMC baseline by +1.69% in HR@10 (0.1187 vs 0.1018) on MovieLens 100K without any training
- Achieves 0.1187 HR@10, performing comparably to strong sequential baselines like GRU4Rec (0.1230) and SASRec (0.1241)
- Improves over Simple Prompting by ~4x (0.1187 vs 0.0297 HR@10) by introducing candidate sets and multi-step reasoning
Breakthrough Assessment
7/10
Demonstrates that LLMs can compete with trained baselines in zero-shot settings if the search space is constrained. Novelty lies in the prompting structure rather than architecture.