📝 Paper Summary
LLM-based Recommendation Systems
Multi-Agent Systems
Location-Based Social Networks (LBSN)
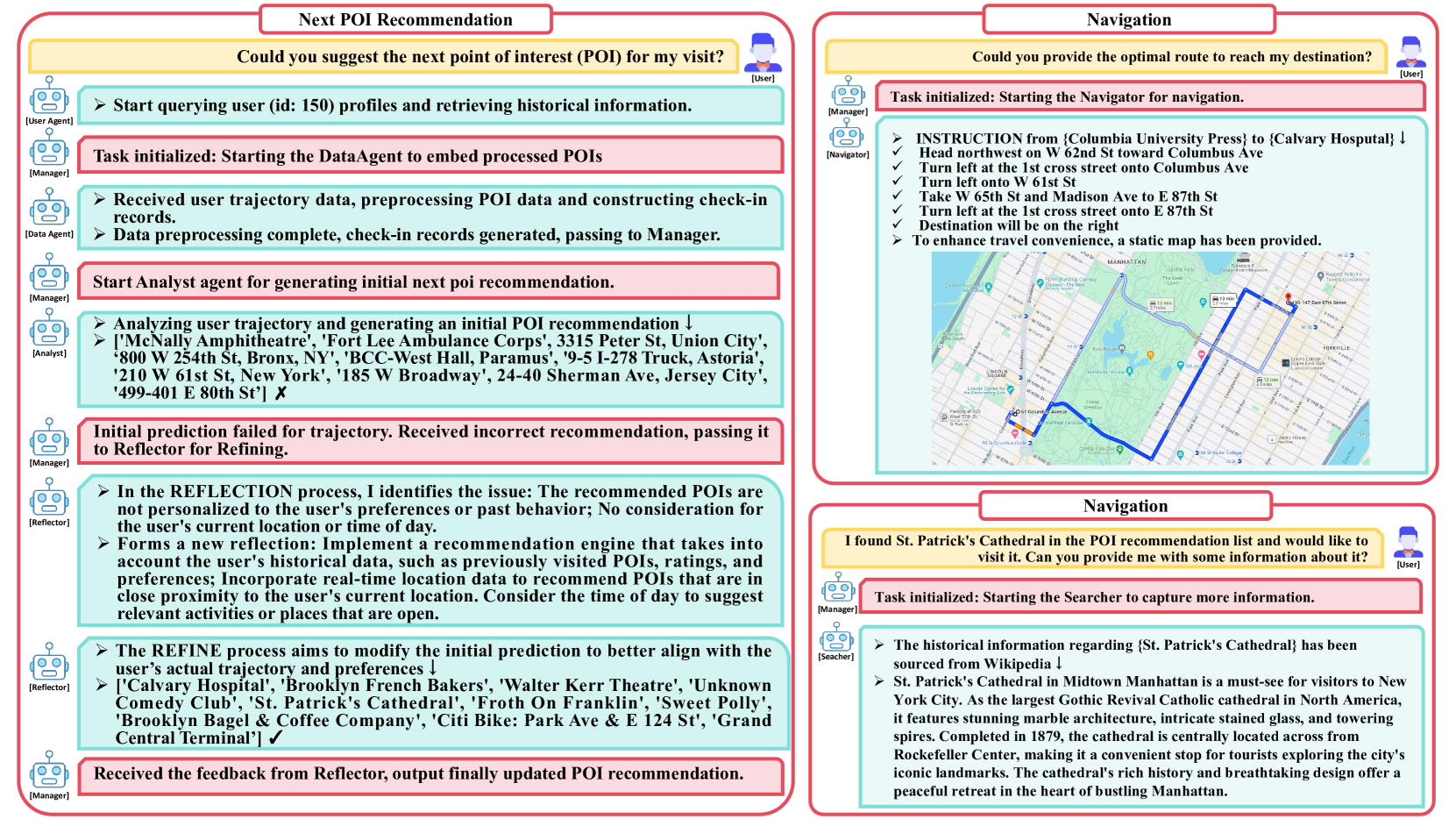
MAS4POI deploys seven specialized LLM agents that collaborate through iterative reflection and refinement to predict a user's next location and provide navigation services.
Core Problem
Traditional POI recommendation methods struggle with cold-start issues, lack interpretability, and often overlook environmental/temporal contexts, while single-LLM approaches can hallucinate or fail to manage complex spatial reasoning tasks.
Why it matters:
- Current deep learning models require extensive labeled datasets and high computational costs, hindering real-time interaction and trust
- Single agents often cannot handle the multifaceted nature of POI tasks (data processing, spatial analysis, user interaction) simultaneously
- Accurate next-location prediction is critical for personalized location-based services like route planning and local advertising
Concrete Example:
A user with limited history (cold start) asks for a recommendation. A standard model might fail due to sparse data. In MAS4POI, the DataAgent extracts available context, the Analyst infers preferences from category patterns, and the Reflector iteratively critiques the initial guess to correct aberrations before the final output.
Key Novelty
Role-Based Multi-Agent Collaboration for Spatial Recommendation
- Specializes LLMs into seven distinct roles (e.g., Analyst, Reflector, Navigator) that handle specific sub-tasks like data preprocessing or route planning
- Implements a 'Reflection and Refinement' mechanism where a Reflector agent critiques the Manager's initial output and iteratively improves it until a stopping condition is met
- Integrates external tools (Amap API, Wikipedia) directly into the agent workflow for real-time navigation and information retrieval
Architecture
The overall framework of MAS4POI, illustrating the interactions between the seven agents (DataAgent, Manager, Analyst, Reflector, UserAgent, Searcher, Navigator) and the flow of data.
Evaluation Highlights
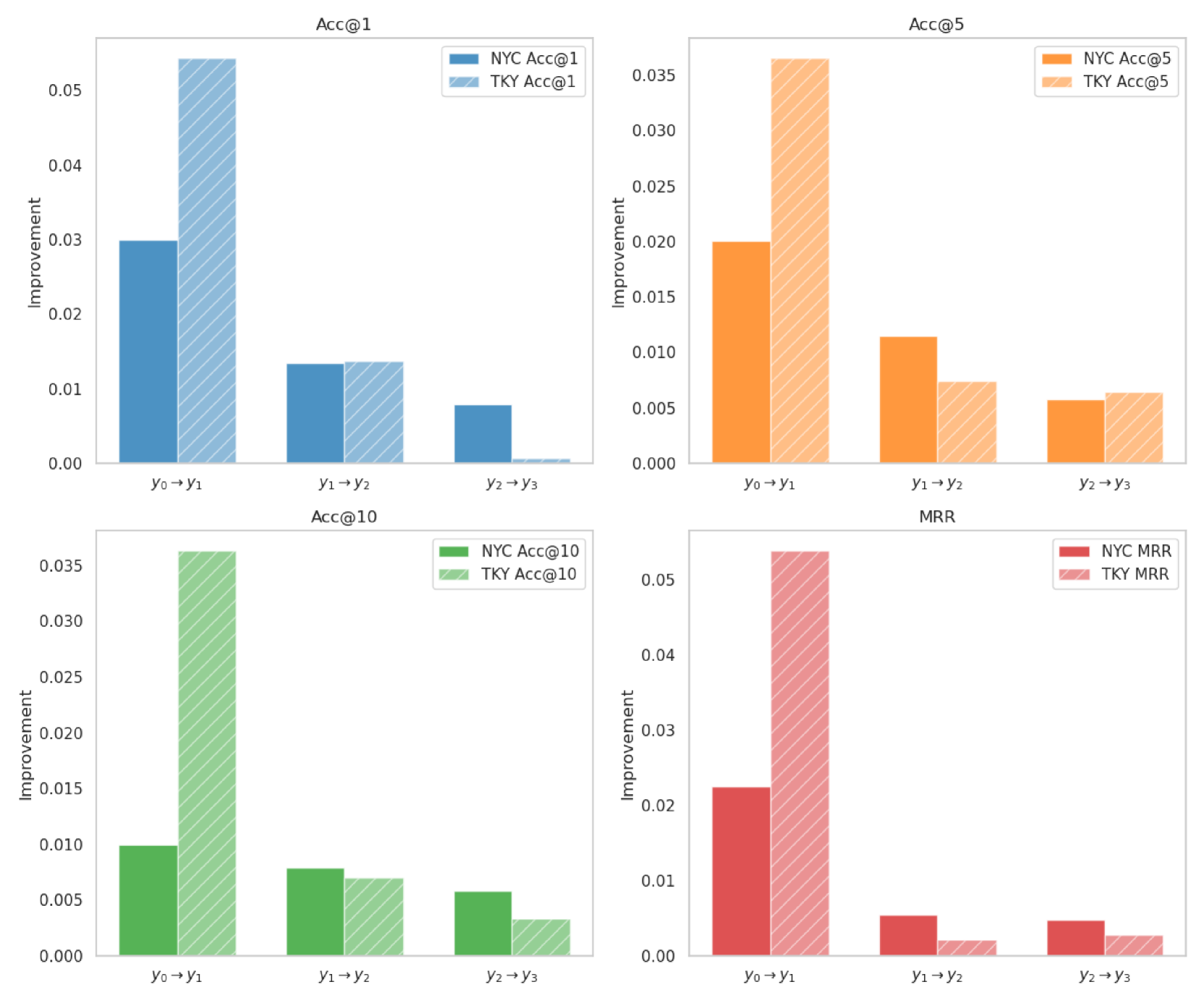
- +30.8% accuracy improvement on the New York dataset compared to the best baseline (LSTPM)
- +24.6% accuracy improvement on the Singapore dataset compared to the best baseline (LSTPM)
- Significant performance gains in Cold Start scenarios (users with <15 records), outperforming baselines like STAN and DeepMove
Breakthrough Assessment
7/10
Strong application of multi-agent patterns to the specific domain of POI recommendation with impressive empirical gains, though the underlying agent architecture (Reflexion-style) is a known pattern applied to a new context.