📝 Paper Summary
LLM-based News Recommendation
Automated Prompt Engineering
RecPrompt improves news recommendation by using an iterative two-LLM loop where a prompt optimizer refines the recommender's instructions based on feedback, alongside a new metric for evaluating topic explanations.
Core Problem
Existing LLM-based news recommenders often fail to surpass deep neural baselines and require labor-intensive manual prompt engineering that may not align with user interests.
Why it matters:
- Fine-tuning LLMs is resource-intensive and requires high-quality rationales which are hard to produce
- Current evaluation metrics focus purely on ranking and lack ground truth for assessing the quality and explainability of generated topic summaries
- Manual prompt design is static and may not optimally leverage the LLM's reasoning capabilities for specific recommendation tasks
Concrete Example:
A user interested in 'Sports' clicks news H1 and H3. A standard recommender might correctly rank news but fail to explain why. RecPrompt's optimizer detects if the 'topics' in the explanation are unclear or misaligned with click behavior and rewrites the prompt to force the recommender to better summarize user-interest topics.
Key Novelty
Self-tuning Prompting Loop (RecPrompt)
- Iterative bootstrapping process involving two LLMs: one acts as the Recommender making predictions, and the other as an Optimizer refining the Recommender's prompt templates
- Introduction of a Monitor component that tracks performance metrics (MRR, nDCG) to accept or reject prompt updates, ensuring monotonic improvement
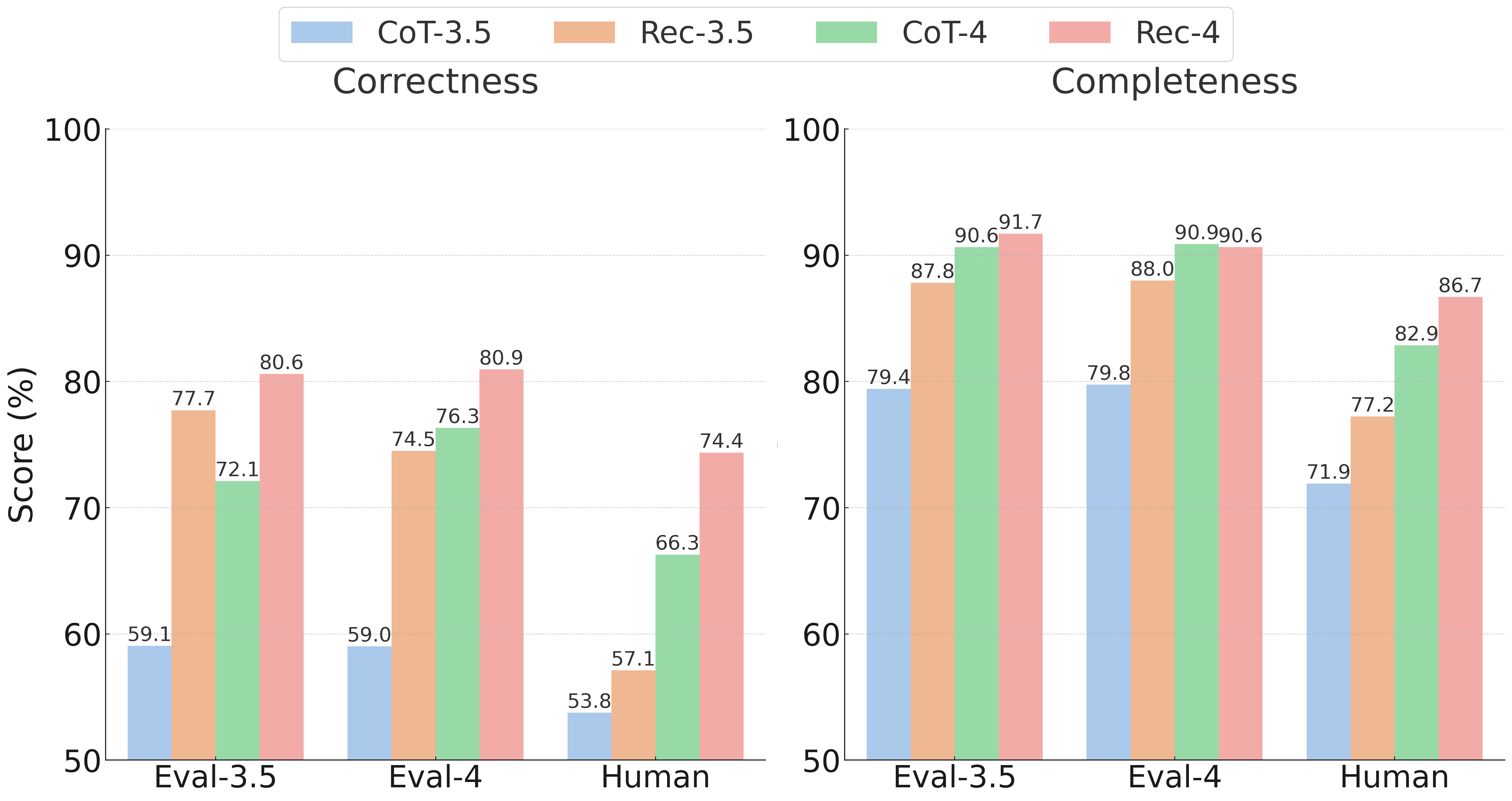
- Development of TopicScore, a novel metric to evaluate the explainability of recommendations by measuring the correctness and completeness of summarized interest topics
Architecture
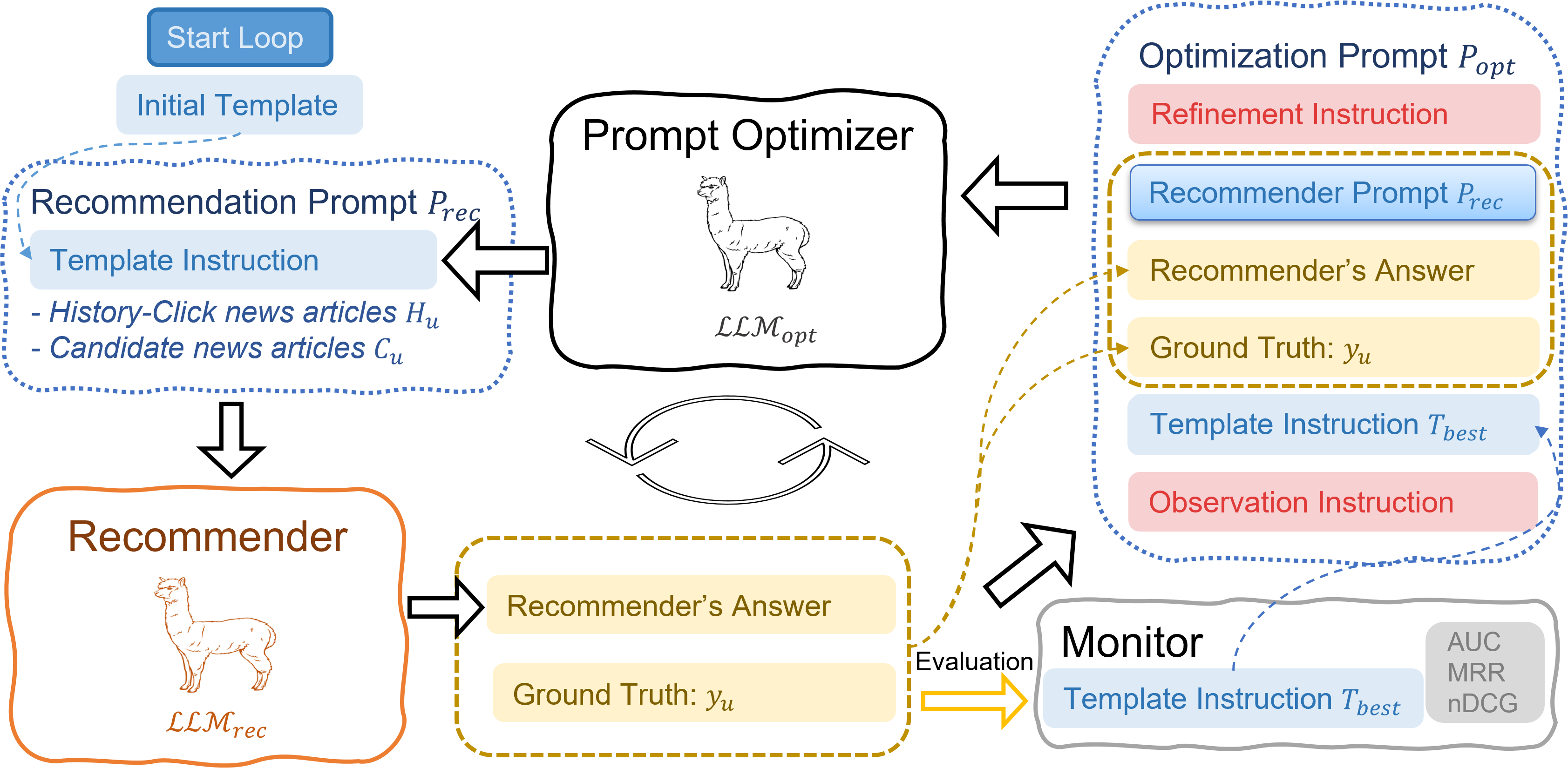
The RecPrompt framework workflow.
Evaluation Highlights
- +3.36% improvement in AUC and +10.49% in MRR compared to traditional deep neural models on the MIND dataset
- CoT-LLM_rec-4 (GPT-4 with Chain-of-Thought) surpasses all deep neural baselines using zero-shot prompting without training on recommendation data
- RecPrompt outperforms standard prompting strategies (Input-Output and Chain-of-Thought) by iteratively refining the instruction template
Breakthrough Assessment
7/10
Strong improvements over deep learning baselines using a novel self-tuning loop. The introduction of an explainability metric (TopicScore) fills a gap, though the method relies on closed-source models (GPT-3.5/4).