📝 Paper Summary
Generative Retrieval
Conversational Recommendation
Music Recommendation
Text2Tracks frames music recommendation as a generative retrieval task where a language model directly generates semantic track identifiers derived from collaborative filtering embeddings, outperforming text-based and integer-based ID strategies.
Core Problem
Standard LLM-based recommendation generates track titles (text) autoregressively, which is slow (many tokens), requires entity resolution to find the actual track ID, and fails to capture semantic similarity between items.
Why it matters:
- Textual titles are inefficient for retrieval because decoding steps scale linearly with title length
- Entity resolution is error-prone when multiple tracks share the same title or artist
- Naive text generation does not leverage the rich collaborative filtering signals available in music recommendation datasets
Concrete Example:
If a user asks for 'upbeat rock', a standard LLM might generate 'Bohemian Rhapsody by Queen'. This requires generating ~10 tokens and then a separate system to map that string to a database ID. If the title is misspelled or ambiguous, the lookup fails.
Key Novelty
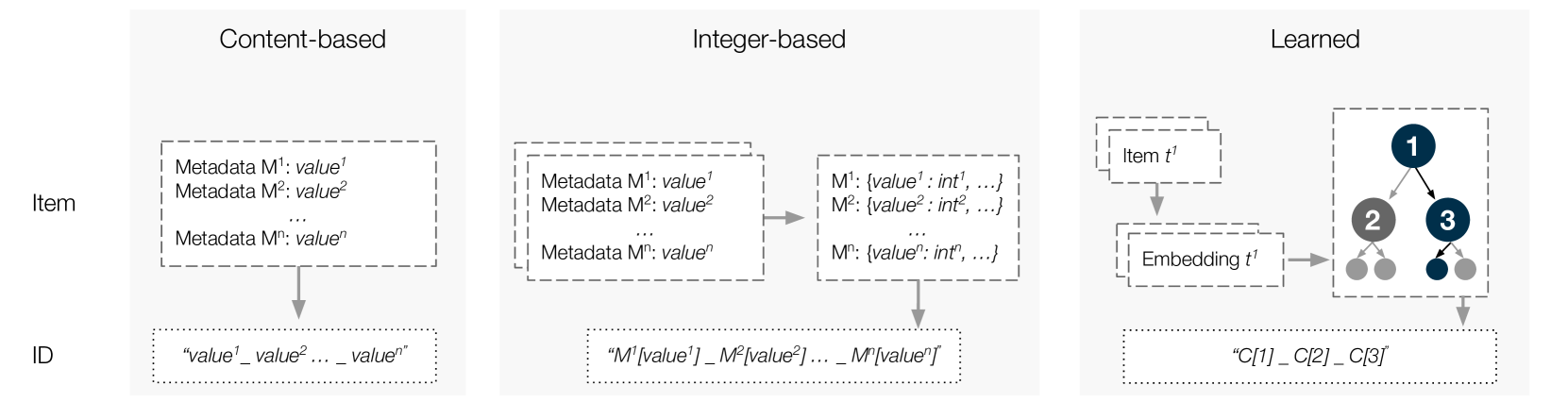
Generative Retrieval with Semantic Track IDs (Text2Tracks)
- Replaces text titles with learned semantic IDs: short sequences of tokens derived from collaborative filtering embeddings (vectors representing listening patterns)
- Discretizes continuous track embeddings into hierarchical tokens using sparse coding, so tracks with similar listening patterns share ID prefixes
- Fine-tunes a single transformer to map natural language prompts directly to these concise track IDs, skipping external entity resolution
Architecture
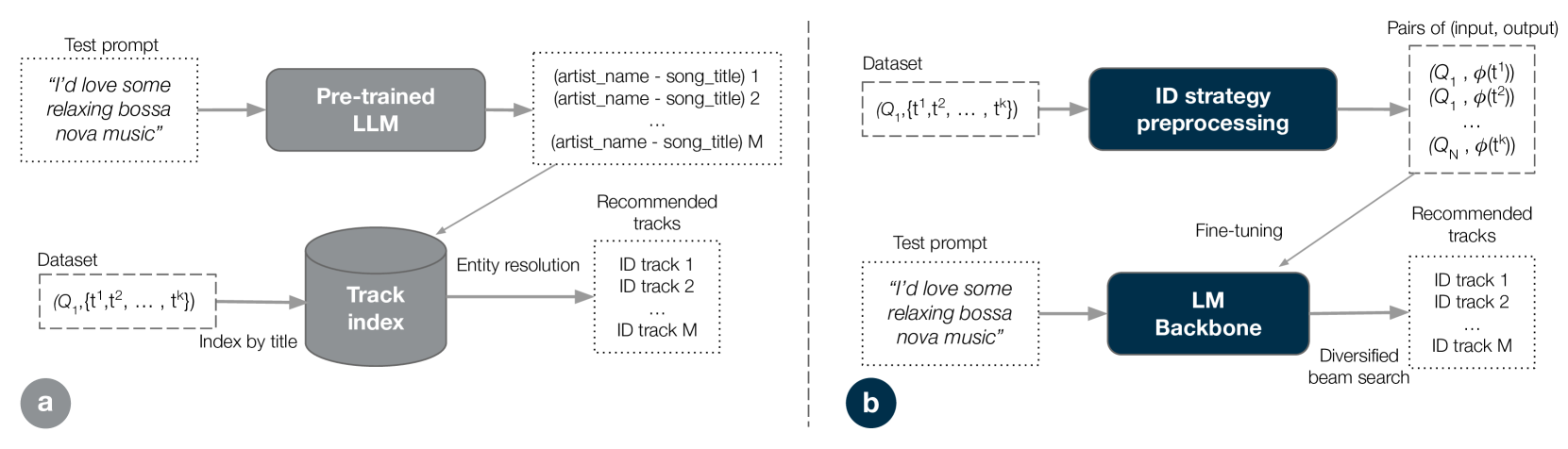
The Text2Tracks training and inference pipeline.
Evaluation Highlights
- Semantic IDs (cf-based) outperform standard artist-name-track-name text generation by ~48% in Hits@10
- Reduces decoding steps by ~7.5x compared to generating full text titles, significantly speeding up inference
- Text2Tracks outperforms strong dense retrieval baselines (Bi-Encoder) and sparse baselines (BM25) on the prompt-to-track retrieval task
Breakthrough Assessment
7/10
Strong application of generative retrieval to the music domain with a novel ID discretization strategy. While generative retrieval is known, the specific adaptation to collaborative filtering embeddings for music IDs effectively solves the latency and entity resolution issues.